24 网络抓取
24.1 引言
本章将向你介绍使用 rvest 进行网络抓取 (web scraping) 的基础知识。网络抓取是从网页中提取数据的一个非常有用的工具。有些网站会提供 API,这是一组结构化的 HTTP 请求,以 JSON 格式返回数据,你可以使用 Chapter 23 中介绍的技术来处理这些数据。如果可能,你应该使用 API 1,因为它通常会为你提供更可靠的数据。然而,不幸的是,使用 Web API 进行编程超出了本书的范围。因此,我们教授的是抓取技术,无论网站是否提供 API,这种技术都适用。
在本章中,我们首先会讨论抓取的伦理和法律问题,然后再深入探讨 HTML 的基础知识。接着,你将学习 CSS 选择器的基础知识,以定位页面上的特定元素,以及如何使用 rvest 函数从 HTML 中提取文本和属性数据并将其导入 R。然后,我们将讨论一些技巧,以帮助你确定所需页面的 CSS 选择器,最后通过几个案例研究结束,并简要讨论动态网站。
24.1.1 先决条件
在本章中,我们将重点介绍 rvest 提供的工具。rvest 是 tidyverse 的一个成员,但不是核心成员,所以你需要显式加载它。我们还将加载完整的 tidyverse,因为在处理我们抓取的数据时,它通常很有用。
24.2 抓取的伦理和法律
在我们开始讨论执行网络抓取所需的代码之前,我们需要谈谈这样做是否合法和合乎道德。总的来说,这两种情况都很复杂。
合法性在很大程度上取决于你所在的地区。然而,作为一般原则,如果数据是公开的、非个人的和事实性的,你很可能是安全的 2。这三个因素很重要,因为它们与网站的服务条款、个人身份信息和版权有关,我们将在下面讨论。
如果数据不是公开的、非个人的或事实性的,或者你抓取数据的目的就是为了赚钱,那么你需要咨询律师。在任何情况下,你都应该尊重托管你正在抓取的页面的服务器资源。最重要的是,这意味着如果你要抓取许多页面,你应该确保在每个请求之间稍作等待。一个简单的方法是使用 Dmytro Perepolkin 的 polite 包。它会自动在请求之间暂停,并缓存结果,这样你就永远不会两次请求同一个页面。
24.2.1 服务条款
如果你仔细观察,你会发现许多网站在页面的某个地方包含一个“条款和条件”或“服务条款”的链接,如果你仔细阅读那个页面,你通常会发现该网站明确禁止网络抓取。这些页面往往是公司提出非常宽泛主张的法律“圈地”。在可能的情况下,尊重这些服务条款是礼貌的,但对任何主张都要持保留态度。
美国法院通常认为,仅仅将服务条款放在网站页脚不足以使你受其约束,例如 HiQ Labs v. LinkedIn。通常,要受服务条款约束,你必须采取一些明确的行动,比如创建账户或勾选一个框。这就是为什么数据是否公开很重要的原因;如果你不需要账户就能访问它们,你就不太可能受服务条款的约束。但请注意,在欧洲情况大不相同,法院认为即使你没有明确同意,服务条款也是可执行的。
24.2.2 个人身份信息
即使数据是公开的,你也应该极其小心地抓取个人身份信息 (personally identifiable information),如姓名、电子邮件地址、电话号码、出生日期等。欧洲对收集或存储此类数据有特别严格的法律 (GDPR),无论你住在哪里,你都可能陷入道德困境。例如,2016 年,一组研究人员抓取了约会网站 OkCupid 上 70,000 人的公开个人资料信息(例如,用户名、年龄、性别、位置等),并在没有任何匿名化尝试的情况下公开发布了这些数据。虽然研究人员认为这样做没有错,因为数据已经是公开的,但这项工作因涉及用户身份可识别性的伦理问题而受到广泛谴责。如果你的工作涉及抓取个人身份信息,我们强烈建议阅读关于 OkCupid 研究 3 以及涉及获取和发布个人身份信息且研究伦理存疑的类似研究的资料。
24.2.3 版权
最后,你还需要担心版权法。版权法很复杂,但值得一看的是美国法律,它准确描述了受保护的内容:“[…] 固定在任何有形表达媒介中的原创作者作品 […]”。然后它继续描述了它适用的具体类别,如文学作品、音乐作品、电影等。值得注意的是,数据不在版权保护之列。这意味着,只要你将抓取限制在事实上,版权保护就不适用。(但请注意,欧洲有一项单独的“特殊权利” (sui generis),用于保护数据库。)
举个简单的例子,在美国,配料和说明的列表不受版权保护,所以版权不能用来保护食谱。但是,如果那份食谱列表伴随着大量新颖的文学内容,那么这些内容是受版权保护的。这就是为什么当你在互联网上寻找食谱时,总是有那么多前置内容的原因。
如果你确实需要抓取原创内容(如文本或图片),你可能仍然受到合理使用原则 (doctrine of fair use) 的保护。合理使用不是一个硬性规定,而是权衡了许多因素。如果你是为了研究或非商业目的收集数据,并且你将抓取的内容限制在所需范围内,那么它更有可能适用。
24.3 HTML 基础
要抓取网页,你首先需要对 HTML 有一点了解,这是一种描述网页的语言。HTML 是超文本标记语言 (HyperText Markup Language) 的缩写,看起来像这样:
<html>
<head>
<title>页面标题</title>
</head>
<body>
<h1 id='first'>一个标题</h1>
<p>一些文本 & <b>一些粗体文本。</b></p>
<img src='myimg.png' width='100' height='100'>
</body>HTML 具有由元素 (elements) 构成的层次结构,元素由一个开始标签 (start tag)(例如 <tag>)、可选的属性 (attributes)(id='first')、一个结束标签 (end tag) 4(例如 </tag>)和内容 (contents)(开始和结束标签之间的所有内容)组成。
由于 < 和 > 用于开始和结束标签,你不能直接写它们。你必须使用 HTML 转义 (escapes) > (大于) 和 < (小于)。并且由于这些转义使用了 &,如果你想要一个字面上的 & 符号,你必须将其转义为 &。有各种各样的 HTML 转义,但你不需要太担心它们,因为 rvest 会自动为你处理。
网络抓取之所以可行,是因为大多数包含你想要抓取的数据的页面通常都有一个一致的结构。
24.3.1 元素
HTML 元素有 100 多种。其中一些最重要的元素是:
每个 HTML 页面都必须在一个
<html>元素中,并且它必须有两个子元素:<head>,包含文档元数据,如页面标题;以及<body>,包含你在浏览器中看到的内容。块级标签,如
<h1>(一级标题)、<section>(区域)、<p>(段落) 和<ol>(有序列表),构成了页面的整体结构。内联标签,如
<b>(粗体)、<i>(斜体) 和<a>(链接),用于格式化块级标签内的文本。
如果你遇到一个你从未见过的标签,你可以通过谷歌搜索来了解它的作用。另一个好的起点是 MDN Web Docs,它描述了几乎所有 Web 编程的方面。
大多数元素在其开始和结束标签之间可以有内容。这个内容可以是文本,也可以是更多的元素。例如,下面的 HTML 包含一个文本段落,其中一个词是粗体的。
<p>
嗨!我的<b>名字</b>是 Hadley。
</p>子元素 (children) 是它包含的元素,所以上面的 <p> 元素有一个子元素,即 <b> 元素。<b> 元素没有子元素,但它有内容(文本“名字”)。
24.3.2 属性
标签可以有命名的属性 (attributes),看起来像 name1='value1' name2='value2'。两个最重要的属性是 id 和 class,它们与 CSS (Cascading Style Sheets) 结合使用,以控制页面的视觉外观。在抓取数据时,这些属性通常很有用。属性还用于记录链接的目的地(<a> 元素的 href 属性)和图像的来源(<img> 元素的 src 属性)。
24.4 提取数据
要开始抓取,你需要你想要抓取的页面的 URL,你通常可以从你的网络浏览器中复制。然后,你需要使用 read_html() 将该页面的 HTML 读入 R。这将返回一个 xml_document 5 对象,然后你将使用 rvest 函数来操作它:
html <- read_html("http://rvest.tidyverse.org/")
html
#> {html_document}
#> <html lang="en">
#> [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UT ...
#> [2] <body>\n <a href="#container" class="visually-hidden-focusable">Ski ...rvest 还包含一个函数,可以让你内联编写 HTML。在本章中,我们将大量使用这个函数,因为我们通过简单的例子来教授各种 rvest 函数的工作方式。
html <- minimal_html("
<p>这是一个段落</p>
<ul>
<li>这是一个项目符号列表</li>
</ul>
")
html
#> {html_document}
#> <html>
#> [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UT ...
#> [2] <body>\n<p>这是一个段落</p>\n <ul>\n<li>这是一个项目符号列表</li>\n </ul>\n</body>现在你已经在 R 中有了 HTML,是时候提取感兴趣的数据了。你将首先学习 CSS 选择器,它允许你识别感兴趣的元素,以及你可以用来从中提取数据的 rvest 函数。然后我们将简要介绍 HTML 表格,它有一些特殊的工具。
24.4.1 查找元素
CSS 是层叠样式表 (cascading style sheets) 的缩写,是一种用于定义 HTML 文档视觉样式的工具。CSS 包括一种用于在页面上选择元素的微型语言,称为 CSS 选择器 (CSS selectors)。CSS 选择器定义了定位 HTML 元素的模式,对于抓取很有用,因为它们提供了一种简洁的方式来描述你想要提取的元素。
我们将在 Section 24.5 中更详细地回到 CSS 选择器,但幸运的是,你只需掌握三个就可以走得很远:
p选择所有<p>元素。.title选择所有class为 “title” 的元素。#title选择id属性等于 “title” 的元素。Id 属性在文档中必须是唯一的,所以这只会选择一个元素。
让我们用一个简单的例子来试试这些选择器:
html <- minimal_html("
<h1>这是一个标题</h1>
<p id='first'>这是一个段落</p>
<p class='important'>这是一个重要的段落</p>
")使用 html_elements() 来查找所有匹配选择器的元素:
html |> html_elements("p")
#> {xml_nodeset (2)}
#> [1] <p id="first">这是一个段落</p>
#> [2] <p class="important">这是一个重要的段落</p>
html |> html_elements(".important")
#> {xml_nodeset (1)}
#> [1] <p class="important">这是一个重要的段落</p>
html |> html_elements("#first")
#> {xml_nodeset (1)}
#> [1] <p id="first">这是一个段落</p>另一个重要的函数是 html_element(),它总是返回与输入相同数量的输出。如果你将它应用于整个文档,它会给你第一个匹配项:
html |> html_element("p")
#> {html_node}
#> <p id="first">当你使用一个不匹配任何元素的选择器时,html_element() 和 html_elements() 之间有一个重要的区别。html_elements() 返回一个长度为 0 的向量,而 html_element() 返回一个缺失值。这一点很快就会变得很重要。
html |> html_elements("b")
#> {xml_nodeset (0)}
html |> html_element("b")
#> {xml_missing}
#> <NA>24.4.2 嵌套选择
在大多数情况下,你会一起使用 html_elements() 和 html_element(),通常使用 html_elements() 来识别将成为观测值的元素,然后使用 html_element() 来查找将成为变量的元素。让我们通过一个简单的例子来看看这个过程。这里我们有一个无序列表 (<ul>),其中每个列表项 (<li>) 都包含一些关于星球大战中四个角色的信息:
html <- minimal_html("
<ul>
<li><b>C-3PO</b> 是一个<i>机器人</i>,重 <span class='weight'>167 kg</span></li>
<li><b>R4-P17</b> 是一个<i>机器人</i></li>
<li><b>R2-D2</b> 是一个<i>机器人</i>,重 <span class='weight'>96 kg</span></li>
<li><b>Yoda</b> 重 <span class='weight'>66 kg</span></li>
</ul>
")我们可以使用 html_elements() 来创建一个向量,其中每个元素对应一个不同的角色:
characters <- html |> html_elements("li")
characters
#> {xml_nodeset (4)}
#> [1] <li>\n<b>C-3PO</b> 是一个<i>机器人</i>,重 <span class="weight">167 kg</span>\ ...
#> [2] <li>\n<b>R4-P17</b> 是一个<i>机器人</i>\n</li>
#> [3] <li>\n<b>R2-D2</b> 是一个<i>机器人</i>,重 <span class="weight">96 kg</span>\n ...
#> [4] <li>\n<b>Yoda</b> 重 <span class="weight">66 kg</span>\n</li>要提取每个角色的名字,我们使用 html_element(),因为当它应用于 html_elements() 的输出时,它保证为每个元素返回一个响应:
characters |> html_element("b")
#> {xml_nodeset (4)}
#> [1] <b>C-3PO</b>
#> [2] <b>R4-P17</b>
#> [3] <b>R2-D2</b>
#> [4] <b>Yoda</b>html_element() 和 html_elements() 之间的区别对于名字来说并不重要,但对于体重来说很重要。我们希望为每个角色获得一个体重,即使没有体重 <span>。这就是 html_element() 所做的:
characters |> html_element(".weight")
#> {xml_nodeset (4)}
#> [1] <span class="weight">167 kg</span>
#> [2] NA
#> [3] <span class="weight">96 kg</span>
#> [4] <span class="weight">66 kg</span>html_elements() 查找所有作为 characters 子元素的体重 <span>。这里只有三个,所以我们失去了名字和体重之间的联系:
characters |> html_elements(".weight")
#> {xml_nodeset (3)}
#> [1] <span class="weight">167 kg</span>
#> [2] <span class="weight">96 kg</span>
#> [3] <span class="weight">66 kg</span>现在你已经选择了感兴趣的元素,你需要提取数据,可以从文本内容或某些属性中提取。
24.4.3 文本和属性
html_text2()6 提取 HTML 元素的纯文本内容:
characters |>
html_element("b") |>
html_text2()
#> [1] "C-3PO" "R4-P17" "R2-D2" "Yoda"
characters |>
html_element(".weight") |>
html_text2()
#> [1] "167 kg" NA "96 kg" "66 kg"注意,任何转义都会被自动处理;你只会在源 HTML 中看到 HTML 转义,而不会在 rvest 返回的数据中看到。
html_attr() 从属性中提取数据:
html <- minimal_html("
<p><a href='https://en.wikipedia.org/wiki/Cat'>猫</a></p>
<p><a href='https://en.wikipedia.org/wiki/Dog'>狗</a></p>
")
html |>
html_elements("p") |>
html_element("a") |>
html_attr("href")
#> [1] "https://en.wikipedia.org/wiki/Cat" "https://en.wikipedia.org/wiki/Dog"html_attr() 总是返回一个字符串,所以如果你正在提取数字或日期,你需要进行一些后处理。
24.4.4 表格
如果幸运的话,你的数据已经存储在 HTML 表格中,那么只需要从该表格中读取即可。在浏览器中识别表格通常很简单:它会有一个行和列的矩形结构,你可以将其复制并粘贴到像 Excel 这样的工具中。
HTML 表格由四个主要元素构成:<table>、<tr>(表格行)、<th>(表格标题)和 <td>(表格数据)。这是一个简单的 HTML 表格,有两列三行:
html <- minimal_html("
<table class='mytable'>
<tr><th>x</th> <th>y</th></tr>
<tr><td>1.5</td> <td>2.7</td></tr>
<tr><td>4.9</td> <td>1.3</td></tr>
<tr><td>7.2</td> <td>8.1</td></tr>
</table>
")rvest 提供了一个知道如何读取这类数据的函数:html_table()。它返回一个列表,其中包含页面上找到的每个表格的一个 tibble。使用 html_element() 来识别你想要提取的表格:
html |>
html_element(".mytable") |>
html_table()
#> # A tibble: 3 × 2
#> x y
#> <dbl> <dbl>
#> 1 1.5 2.7
#> 2 4.9 1.3
#> 3 7.2 8.1注意 x 和 y 已经自动转换为数字。这种自动转换并不总是有效,所以在更复杂的场景中,你可能需要使用 convert = FALSE 关闭它,然后自己进行转换。
24.5 找到正确的选择器
找出你需要的数据的选择器通常是问题中最难的部分。你通常需要进行一些实验,才能找到一个既具体(即它不选择你不在乎的东西)又敏感(即它确实选择了你关心的所有东西)的选择器。大量的反复试验是这个过程的正常部分!有两个主要工具可以帮助你完成这个过程:SelectorGadget 和你浏览器的开发者工具。
SelectorGadget 是一个 javascript 书签工具,它会根据你提供的正面和负面例子自动生成 CSS 选择器。它并不总是有效,但当它有效时,简直是魔法!你可以通过阅读 https://rvest.tidyverse.org/articles/selectorgadget.html 或观看 Mine 在 https://www.youtube.com/watch?v=PetWV5g1Xsc 上的视频来学习如何安装和使用 SelectorGadget。
每个现代浏览器都带有一些面向开发者的工具包,但我们推荐 Chrome,即使它不是你的常规浏览器:它的 Web 开发者工具是最好的之一,而且立即可用。在页面上的一个元素上右键单击,然后点击 Inspect (检查)。这将打开一个可展开的完整 HTML 页面视图,并以你刚刚点击的元素为中心。你可以用它来探索页面,并了解哪些选择器可能有效。要特别注意 class 和 id 属性,因为它们通常用于形成页面的视觉结构,因此是提取你正在寻找的数据的好工具。
在 Elements (元素) 视图中,你还可以右键单击一个元素并选择 Copy as Selector (复制为选择器),以生成一个将唯一标识感兴趣元素的选择器。
如果 SelectorGadget 或 Chrome DevTools 生成了一个你看不懂的 CSS 选择器,可以试试 Selectors Explained,它将 CSS 选择器翻译成通俗易懂的英语。如果你发现自己经常这样做,你可能想更多地了解 CSS 选择器。我们推荐从有趣的 CSS dinner 教程开始,然后参考 MDN web docs。
24.6 整合所有内容
让我们把所有这些整合起来,抓取一些网站。当你运行这些例子时,它们可能不再有效——这是网络抓取的根本挑战;如果网站的结构改变了,你就必须改变你的抓取代码。
24.6.1 星球大战
rvest 在 vignette("starwars") 中包含了一个非常简单的例子。这是一个简单的页面,HTML 最少,所以是一个很好的起点。我鼓励你现在就导航到那个页面,并使用“检查元素”来检查一个作为星球大战电影标题的标题。使用键盘或鼠标来探索 HTML 的层次结构,看看你是否能感觉到每部电影使用的共享结构。
你应该能看到每部电影都有一个共享的结构,看起来像这样:
<section>
<h2 data-id="1">The Phantom Menace</h2>
<p>Released: 1999-05-19</p>
<p>Director: <span class="director">George Lucas</span></p>
<div class="crawl">
<p>...</p>
<p>...</p>
<p>...</p>
</div>
</section>我们的目标是将这些数据转换成一个 7 行的数据框,包含 title、year、director 和 intro 变量。我们将从读取 HTML 并提取所有 <section> 元素开始:
url <- "https://rvest.tidyverse.org/articles/starwars.html"
html <- read_html(url)
section <- html |> html_elements("section")
section
#> {xml_nodeset (7)}
#> [1] <section><h2 data-id="1">\nThe Phantom Menace\n</h2>\n<p>\nReleased: 1 ...
#> [2] <section><h2 data-id="2">\nAttack of the Clones\n</h2>\n<p>\nReleased: ...
#> [3] <section><h2 data-id="3">\nRevenge of the Sith\n</h2>\n<p>\nReleased: ...
#> [4] <section><h2 data-id="4">\nA New Hope\n</h2>\n<p>\nReleased: 1977-05-2 ...
#> [5] <section><h2 data-id="5">\nThe Empire Strikes Back\n</h2>\n<p>\nReleas ...
#> [6] <section><h2 data-id="6">\nReturn of the Jedi\n</h2>\n<p>\nReleased: 1 ...
#> [7] <section><h2 data-id="7">\nThe Force Awakens\n</h2>\n<p>\nReleased: 20 ...这检索到了七个元素,与该页面上找到的七部电影相匹配,这表明使用 section 作为选择器是好的。提取单个元素很简单,因为数据总是可以在文本中找到。只需要找到正确的选择器:
section |> html_element("h2") |> html_text2()
#> [1] "The Phantom Menace" "Attack of the Clones"
#> [3] "Revenge of the Sith" "A New Hope"
#> [5] "The Empire Strikes Back" "Return of the Jedi"
#> [7] "The Force Awakens"
section |> html_element(".director") |> html_text2()
#> [1] "George Lucas" "George Lucas" "George Lucas"
#> [4] "George Lucas" "Irvin Kershner" "Richard Marquand"
#> [7] "J. J. Abrams"一旦我们为每个组件都这样做了,我们就可以将所有结果包装成一个 tibble:
tibble(
title = section |>
html_element("h2") |>
html_text2(),
released = section |>
html_element("p") |>
html_text2() |>
str_remove("Released: ") |>
parse_date(),
director = section |>
html_element(".director") |>
html_text2(),
intro = section |>
html_element(".crawl") |>
html_text2()
)
#> # A tibble: 7 × 4
#> title released director intro
#> <chr> <date> <chr> <chr>
#> 1 The Phantom Menace 1999-05-19 George Lucas "Turmoil has engulfed …
#> 2 Attack of the Clones 2002-05-16 George Lucas "There is unrest in th…
#> 3 Revenge of the Sith 2005-05-19 George Lucas "War! The Republic is …
#> 4 A New Hope 1977-05-25 George Lucas "It is a period of civ…
#> 5 The Empire Strikes Back 1980-05-17 Irvin Kershner "It is a dark time for…
#> 6 Return of the Jedi 1983-05-25 Richard Marquand "Luke Skywalker has re…
#> # ℹ 1 more row我们对 released 做了一点额外的处理,以得到一个在我们后续分析中易于使用的变量。
24.6.2 IMDB 热门电影
对于我们的下一个任务,我们将处理一个稍微棘手一点的问题,从互联网电影数据库 (IMDb) 中提取前 250 部电影。在我们写这一章的时候,页面看起来像 Figure 24.1。
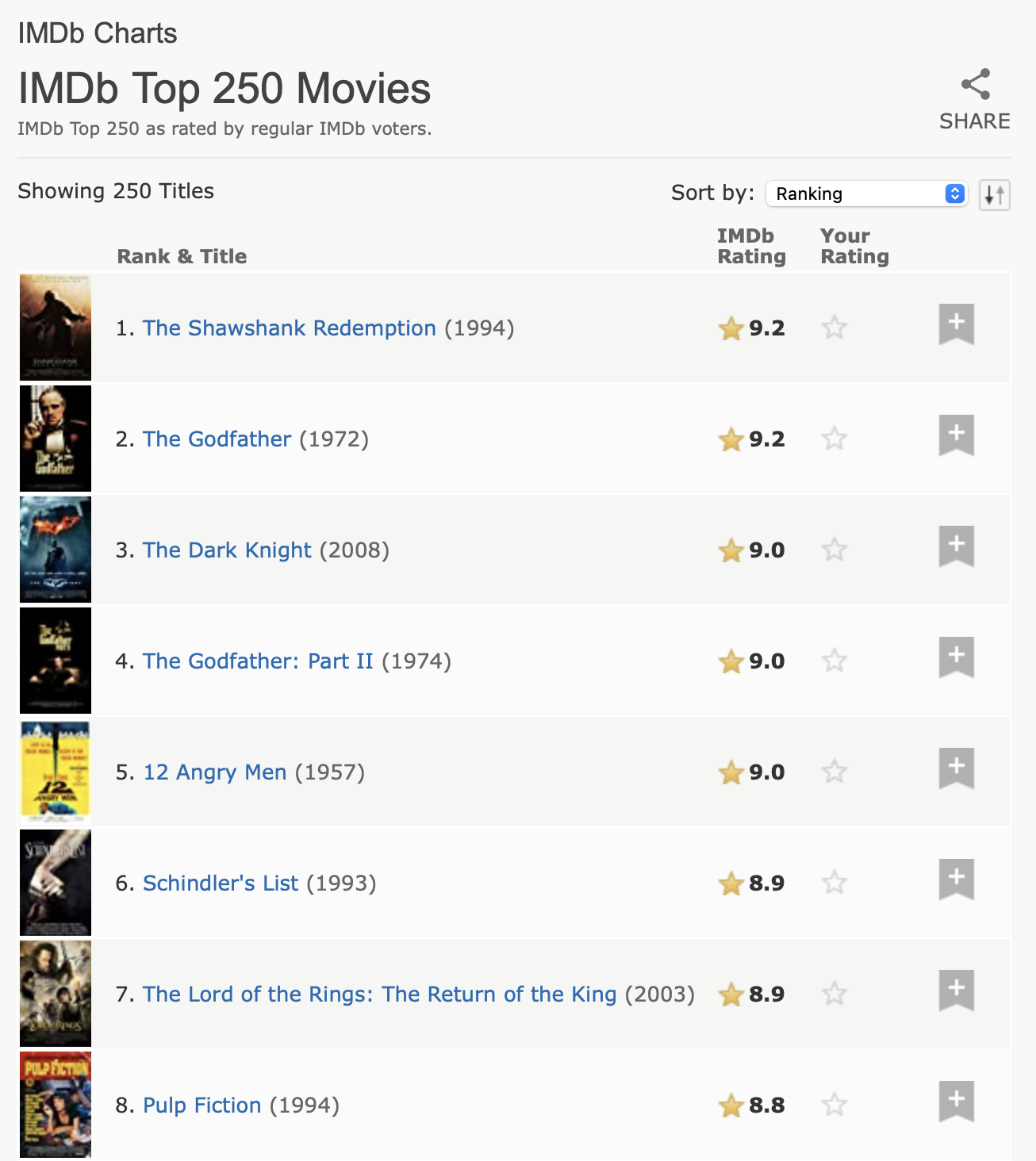
这个数据有清晰的表格结构,所以值得从 html_table() 开始:
url <- "https://web.archive.org/web/20220201012049/https://www.imdb.com/chart/top/"
html <- read_html(url)
table <- html |>
html_element("table") |>
html_table()
table
#> # A tibble: 250 × 5
#> `` `Rank & Title` `IMDb Rating` `Your Rating` ``
#> <lgl> <chr> <dbl> <chr> <lgl>
#> 1 NA "1.\n The Shawshank Redempt… 9.2 "12345678910\n… NA
#> 2 NA "2.\n The Godfather\n … 9.1 "12345678910\n… NA
#> 3 NA "3.\n The Godfather: Part I… 9 "12345678910\n… NA
#> 4 NA "4.\n The Dark Knight\n … 9 "12345678910\n… NA
#> 5 NA "5.\n 12 Angry Men\n … 8.9 "12345678910\n… NA
#> 6 NA "6.\n Schindler's List\n … 8.9 "12345678910\n… NA
#> # ℹ 244 more rows这包含了一些空列,但总的来说,它很好地捕捉了表格中的信息。然而,我们需要做一些更多的处理,使其更易于使用。首先,我们将重命名列,使其更易于使用,并删除排名和标题中多余的空格。我们将使用 select()(而不是 rename())一步完成重命名和选择这两列。然后我们将删除换行符和多余的空格,然后应用 separate_wider_regex()(来自 Section 15.3.4)将标题、年份和排名提取到它们自己的变量中。
ratings <- table |>
select(
rank_title_year = `Rank & Title`,
rating = `IMDb Rating`
) |>
mutate(
rank_title_year = str_replace_all(rank_title_year, "\n +", " ")
) |>
separate_wider_regex(
rank_title_year,
patterns = c(
rank = "\\d+", "\\. ",
title = ".+", " +\\(",
year = "\\d+", "\\)"
)
)
ratings
#> # A tibble: 250 × 4
#> rank title year rating
#> <chr> <chr> <chr> <dbl>
#> 1 1 The Shawshank Redemption 1994 9.2
#> 2 2 The Godfather 1972 9.1
#> 3 3 The Godfather: Part II 1974 9
#> 4 4 The Dark Knight 2008 9
#> 5 5 12 Angry Men 1957 8.9
#> 6 6 Schindler's List 1993 8.9
#> # ℹ 244 more rows即使在这种大部分数据来自表格单元格的情况下,查看原始 HTML 仍然是值得的。如果你这样做,你会发现我们可以通过使用其中一个属性来添加一些额外的数据。这是值得花点时间探索页面源代码的原因之一;你可能会找到额外的数据,或者找到一个稍微容易一些的解析路径。
html |>
html_elements("td strong") |>
head() |>
html_attr("title")
#> [1] "9.2 based on 2,536,415 user ratings"
#> [2] "9.1 based on 1,745,675 user ratings"
#> [3] "9.0 based on 1,211,032 user ratings"
#> [4] "9.0 based on 2,486,931 user ratings"
#> [5] "8.9 based on 749,563 user ratings"
#> [6] "8.9 based on 1,295,705 user ratings"我们可以将此与表格数据结合起来,并再次应用 separate_wider_regex() 来提取我们关心的数据:
ratings |>
mutate(
rating_n = html |> html_elements("td strong") |> html_attr("title")
) |>
separate_wider_regex(
rating_n,
patterns = c(
"[0-9.]+ based on ",
number = "[0-9,]+",
" user ratings"
)
) |>
mutate(
number = parse_number(number)
)
#> # A tibble: 250 × 5
#> rank title year rating number
#> <chr> <chr> <chr> <dbl> <dbl>
#> 1 1 The Shawshank Redemption 1994 9.2 2536415
#> 2 2 The Godfather 1972 9.1 1745675
#> 3 3 The Godfather: Part II 1974 9 1211032
#> 4 4 The Dark Knight 2008 9 2486931
#> 5 5 12 Angry Men 1957 8.9 749563
#> 6 6 Schindler's List 1993 8.9 1295705
#> # ℹ 244 more rows24.7 动态网站
到目前为止,我们专注于那些 html_elements() 返回你在浏览器中看到的内容的网站,并讨论了如何解析其返回的内容以及如何将这些信息组织成整洁的数据框。然而,有时你会遇到一个网站,其中 html_elements() 和相关函数返回的内容与你在浏览器中看到的完全不同。在许多情况下,这是因为你试图抓取一个用 javascript 动态生成页面内容的网站。这目前不适用于 rvest,因为 rvest 下载的是原始 HTML,不运行任何 javascript。
抓取这类网站仍然是可能的,但 rvest 需要使用一个更昂贵的过程:完全模拟网络浏览器,包括运行所有 javascript。在撰写本文时,此功能尚不可用,但这是我们正在积极开发的内容,可能在你阅读本文时已经可用。它使用了 chromote 包,该包实际上在后台运行 Chrome 浏览器,并为你提供了与网站交互的额外工具,就像人类输入文本和点击按钮一样。查看 rvest 网站了解更多详情。
24.8 总结
在本章中,你学习了为什么、为什么不以及如何从网页上抓取数据。首先,你学习了 HTML 的基础知识和使用 CSS 选择器来引用特定元素,然后你学习了使用 rvest 包将数据从 HTML 中提取到 R。接着,我们通过两个案例研究演示了网络抓取:一个是在 rvest 包网站上抓取星球大战电影数据的简单场景,另一个是从 IMDB 抓取前 250 部电影的更复杂场景。
从网络上抓取数据的技术细节可能很复杂,尤其是在处理网站时,然而法律和伦理方面的考虑可能更为复杂。在你开始抓取数据之前,了解这两方面的情况对你来说很重要。
这就结束了本书的导入部分,你已经学习了将数据从它所在的地方(电子表格、数据库、JSON 文件和网站)导入到 R 中的整洁形式的技术。现在是时候将我们的目光转向一个新的主题:充分利用 R 作为一种编程语言。
许多流行的 API 已经有对应的 CRAN 包,所以可以先做一些研究!↩︎
显然我们不是律师,这也不是法律建议。但这是我们在阅读了大量关于这个主题的资料后能给出的最好总结。↩︎
《连线》杂志发表了一篇关于 OkCupid 研究的文章,https://www.wired.com/2016/05/okcupid-study-reveals-perils-big-data-science。↩︎
许多标签(包括
<p>和<li>)不需要结束标签,但我们认为最好还是加上,因为这能让 HTML 的结构看得更清楚一些。↩︎rvest 也提供了
html_text(),但你几乎总是应该使用html_text2(),因为它在将嵌套的 HTML 转换为文本方面做得更好。↩︎