20 电子表格
20.1 引言
在 Chapter 7 中,你学习了如何从像 .csv 和 .tsv 这样的纯文本文件导入数据。现在是时候学习如何从电子表格中获取数据了,无论是 Excel 电子表格还是谷歌表格 (Google Sheet)。这将在你于 Chapter 7 中学到的许多知识的基础上进行,但我们也将讨论处理来自电子表格的数据时需要考虑的额外因素和复杂性。
如果你或你的合作者正在使用电子表格来组织数据,我们强烈建议阅读 Karl Broman 和 Kara Woo 的论文“电子表格中的数据组织”(Data Organization in Spreadsheets):https://doi.org/10.1080/00031305.2017.1375989。这篇论文中提出的最佳实践将在你将数据从电子表格导入 R 进行分析和可视化时为你省去很多麻烦。
20.2 Excel
Microsoft Excel 是一款广泛使用的电子表格软件程序,数据在电子表格文件中的工作表 (worksheets) 里进行组织。
20.2.1 前提条件
在本节中,你将学习如何使用 readxl 包在 R 中加载来自 Excel 电子表格的数据。这个包不是 tidyverse 的核心包,所以你需要显式地加载它,但当你安装 tidyverse 包时它会自动被安装。稍后,我们还将使用 writexl 包,它允许我们创建 Excel 电子表格。
20.2.2 入门
readxl 的大部分函数允许你将 Excel 电子表格加载到 R 中:
-
read_xls()读取xls格式的 Excel 文件。 -
read_xlsx()读取xlsx格式的 Excel 文件。 -
read_excel()可以读取xls和xlsx两种格式的文件。它会根据输入来猜测文件类型。
这些函数的语法都与我们之前介绍的用于读取其他类型文件的函数类似,例如 read_csv()、read_table() 等。在本章的其余部分,我们将重点使用 read_excel()。
20.2.3 读取 Excel 电子表格
Figure 20.1 展示了我们即将读入 R 的电子表格在 Excel 中的样子。这个电子表格可以从 https://docs.google.com/spreadsheets/d/1V1nPp1tzOuutXFLb3G9Eyxi3qxeEhnOXUzL5_BcCQ0w/ 下载为 Excel 文件。
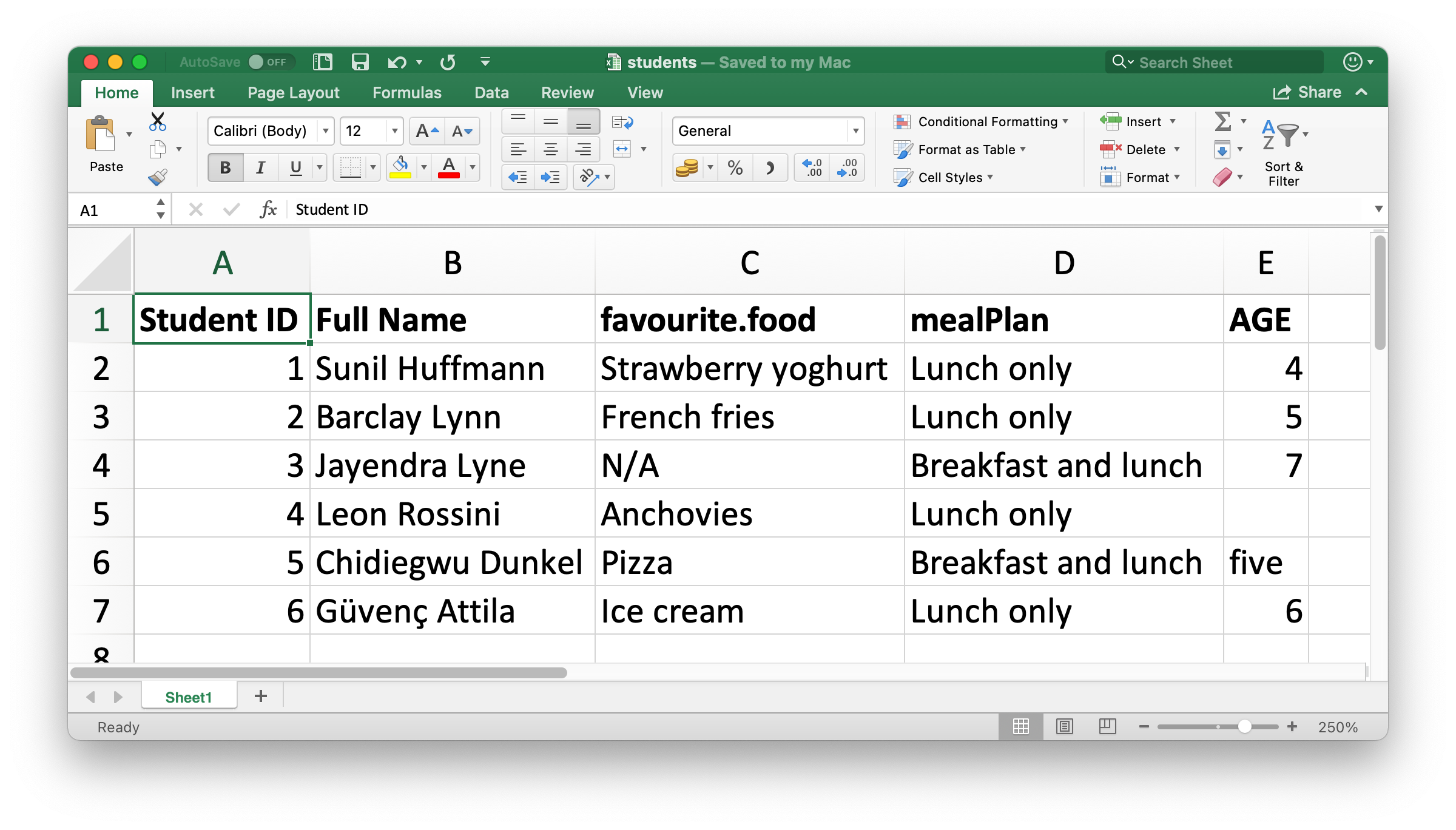
read_excel() 的第一个参数是要读取的文件的路径。
students <- read_excel("data/students.xlsx")read_excel() 会将文件读作一个 tibble。
students
#> # A tibble: 6 × 5
#> `Student ID` `Full Name` favourite.food mealPlan AGE
#> <dbl> <chr> <chr> <chr> <chr>
#> 1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4
#> 2 2 Barclay Lynn French fries Lunch only 5
#> 3 3 Jayendra Lyne N/A Breakfast and lunch 7
#> 4 4 Leon Rossini Anchovies Lunch only <NA>
#> 5 5 Chidiegwu Dunkel Pizza Breakfast and lunch five
#> 6 6 Güvenç Attila Ice cream Lunch only 6数据中有六名学生,每名学生有五个变量。然而,这个数据集中有几件事情我们可能想要处理:
-
列名各式各样,不统一。你可以提供遵循一致格式的列名;我们推荐使用
col_names参数来指定snake_case(蛇形命名法) 格式的列名。read_excel( "data/students.xlsx", col_names = c("student_id", "full_name", "favourite_food", "meal_plan", "age") ) #> # A tibble: 7 × 5 #> student_id full_name favourite_food meal_plan age #> <chr> <chr> <chr> <chr> <chr> #> 1 Student ID Full Name favourite.food mealPlan AGE #> 2 1 Sunil Huffmann Strawberry yoghurt Lunch only 4 #> 3 2 Barclay Lynn French fries Lunch only 5 #> 4 3 Jayendra Lyne N/A Breakfast and lunch 7 #> 5 4 Leon Rossini Anchovies Lunch only <NA> #> 6 5 Chidiegwu Dunkel Pizza Breakfast and lunch five #> 7 6 Güvenç Attila Ice cream Lunch only 6不幸的是,这并没有完全解决问题。我们现在有了想要的变量名,但之前作为标题行的那一行现在作为第一个观测值出现在数据中。你可以使用
skip参数明确跳过那一行。read_excel( "data/students.xlsx", col_names = c("student_id", "full_name", "favourite_food", "meal_plan", "age"), skip = 1 ) #> # A tibble: 6 × 5 #> student_id full_name favourite_food meal_plan age #> <dbl> <chr> <chr> <chr> <chr> #> 1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4 #> 2 2 Barclay Lynn French fries Lunch only 5 #> 3 3 Jayendra Lyne N/A Breakfast and lunch 7 #> 4 4 Leon Rossini Anchovies Lunch only <NA> #> 5 5 Chidiegwu Dunkel Pizza Breakfast and lunch five #> 6 6 Güvenç Attila Ice cream Lunch only 6 -
在
favourite_food列中,其中一个观测值是N/A,代表“不可用”(not available),但它目前没有被识别为NA(注意这个N/A和列表中第四名学生的年龄NA之间的区别)。你可以使用na参数指定哪些字符串应该被识别为NA。默认情况下,只有""(空字符串,或者在从电子表格读取时,是一个空单元格或带有公式=NA()的单元格)被识别为NA。read_excel( "data/students.xlsx", col_names = c("student_id", "full_name", "favourite_food", "meal_plan", "age"), skip = 1, na = c("", "N/A") ) #> # A tibble: 6 × 5 #> student_id full_name favourite_food meal_plan age #> <dbl> <chr> <chr> <chr> <chr> #> 1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4 #> 2 2 Barclay Lynn French fries Lunch only 5 #> 3 3 Jayendra Lyne <NA> Breakfast and lunch 7 #> 4 4 Leon Rossini Anchovies Lunch only <NA> #> 5 5 Chidiegwu Dunkel Pizza Breakfast and lunch five #> 6 6 Güvenç Attila Ice cream Lunch only 6 -
另一个遗留问题是
age被读作字符变量,但它真的应该是数值型。就像使用read_csv()及其系列函数从平面文件读取数据一样,你可以向read_excel()提供一个col_types参数,并为你读入的变量指定列类型。不过,语法有点不同。你的选项是"skip"、"guess"、"logical"、"numeric"、"date"、"text"或"list"。read_excel( "data/students.xlsx", col_names = c("student_id", "full_name", "favourite_food", "meal_plan", "age"), skip = 1, na = c("", "N/A"), col_types = c("numeric", "text", "text", "text", "numeric") ) #> Warning: Expecting numeric in E6 / R6C5: got 'five' #> # A tibble: 6 × 5 #> student_id full_name favourite_food meal_plan age #> <dbl> <chr> <chr> <chr> <dbl> #> 1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4 #> 2 2 Barclay Lynn French fries Lunch only 5 #> 3 3 Jayendra Lyne <NA> Breakfast and lunch 7 #> 4 4 Leon Rossini Anchovies Lunch only NA #> 5 5 Chidiegwu Dunkel Pizza Breakfast and lunch NA #> 6 6 Güvenç Attila Ice cream Lunch only 6然而,这也没有产生我们期望的结果。通过指定
age应该是数值型,我们将一个带有非数值条目(其值为five)的单元格变成了NA。在这种情况下,我们应该将age读作"text",然后在数据加载到 R 后再进行更改。students <- read_excel( "data/students.xlsx", col_names = c("student_id", "full_name", "favourite_food", "meal_plan", "age"), skip = 1, na = c("", "N/A"), col_types = c("numeric", "text", "text", "text", "text") ) students <- students |> mutate( age = if_else(age == "five", "5", age), age = parse_number(age) ) students #> # A tibble: 6 × 5 #> student_id full_name favourite_food meal_plan age #> <dbl> <chr> <chr> <chr> <dbl> #> 1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4 #> 2 2 Barclay Lynn French fries Lunch only 5 #> 3 3 Jayendra Lyne <NA> Breakfast and lunch 7 #> 4 4 Leon Rossini Anchovies Lunch only NA #> 5 5 Chidiegwu Dunkel Pizza Breakfast and lunch 5 #> 6 6 Güvenç Attila Ice cream Lunch only 6
我们通过多个步骤和反复试错才将数据加载成我们想要的确切格式,这并不意外。数据科学是一个迭代的过程,与从其他纯文本、矩形数据文件读取数据相比,从电子表格读取数据时的迭代过程可能更加繁琐,因为人们倾向于将数据输入电子表格,并不仅将其用于数据存储,还用于共享和交流。
除非你加载并查看数据,否则没有办法确切知道数据会是什么样子。嗯,实际上有一种方法。你可以在 Excel 中打开文件并看一眼。如果你打算这样做,我们建议复制一份 Excel 文件进行交互式打开和浏览,同时保持原始数据文件不变,并从这个未动过的文件中读取到 R。这将确保你在检查电子表格时不会意外覆盖任何内容。你也不应该害怕做我们在这里做的事情:加载数据,看一眼,调整你的代码,再次加载,重复这个过程直到你对结果满意为止。
20.2.4 读取工作表
电子表格与平面文件的一个重要区别是多个工作表 (sheets) 的概念。Figure 20.2 展示了一个包含多个工作表的 Excel 电子表格。数据来自 palmerpenguins 包,你可以从 https://docs.google.com/spreadsheets/d/1aFu8lnD_g0yjF5O-K6SFgSEWiHPpgvFCF0NY9D6LXnY/ 下载这个电子表格作为 Excel 文件。每个工作表包含了来自不同岛屿的企鹅信息,这些岛屿是数据收集的地点。
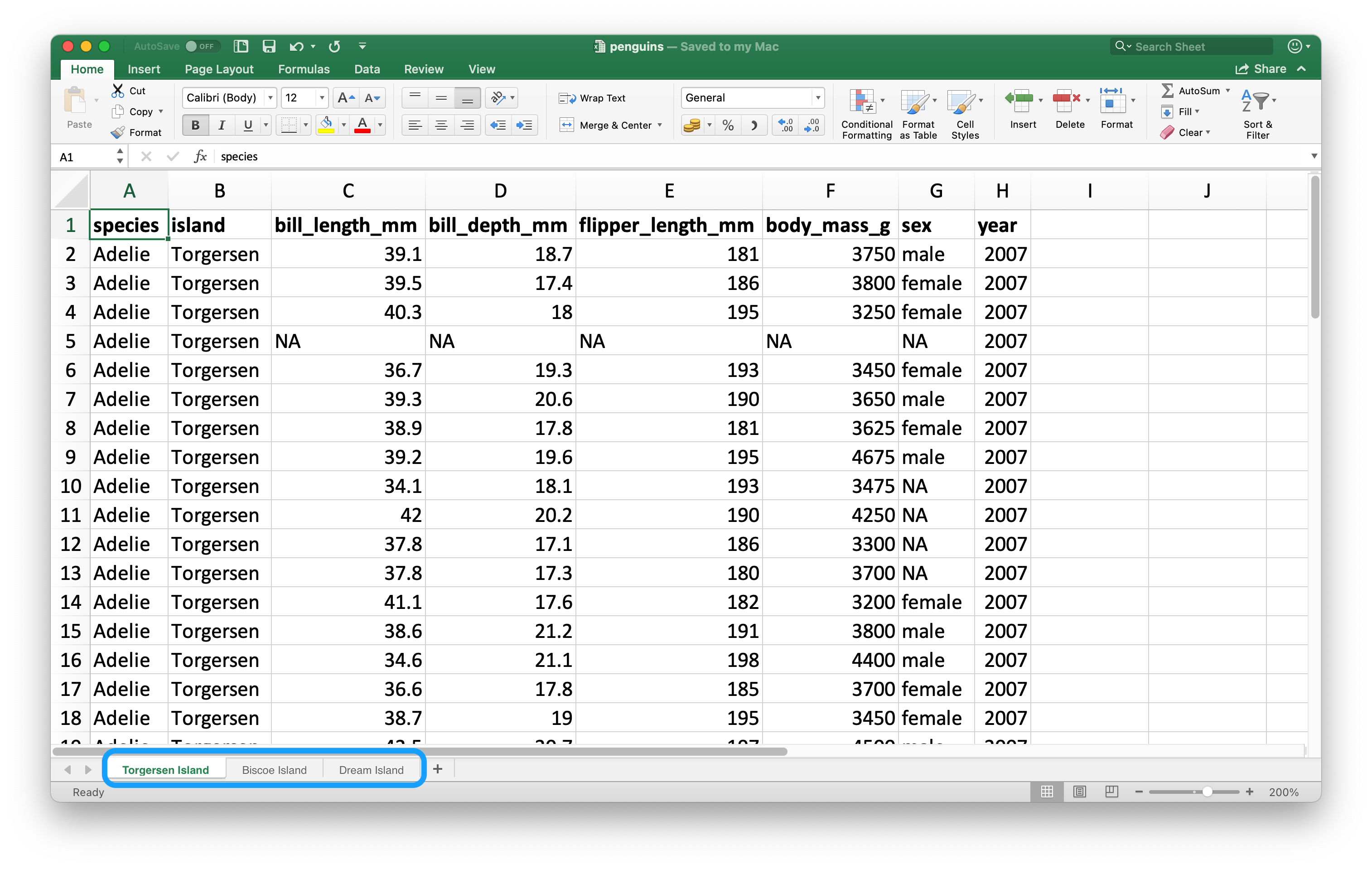
你可以使用 read_excel() 中的 sheet 参数从电子表格中读取单个工作表。默认情况下,也就是我们到目前为止一直依赖的,是第一个工作表。
read_excel("data/penguins.xlsx", sheet = "Torgersen Island")
#> # A tibble: 52 × 8
#> species island bill_length_mm bill_depth_mm flipper_length_mm
#> <chr> <chr> <chr> <chr> <chr>
#> 1 Adelie Torgersen 39.1 18.7 181
#> 2 Adelie Torgersen 39.5 17.399999999999999 186
#> 3 Adelie Torgersen 40.299999999999997 18 195
#> 4 Adelie Torgersen NA NA NA
#> 5 Adelie Torgersen 36.700000000000003 19.3 193
#> 6 Adelie Torgersen 39.299999999999997 20.6 190
#> # ℹ 46 more rows
#> # ℹ 3 more variables: body_mass_g <chr>, sex <chr>, year <dbl>一些看起来包含数值数据的变量被读作字符型,因为字符串 "NA" 没有被识别为真正的 NA。
penguins_torgersen <- read_excel("data/penguins.xlsx", sheet = "Torgersen Island", na = "NA")
penguins_torgersen
#> # A tibble: 52 × 8
#> species island bill_length_mm bill_depth_mm flipper_length_mm
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Adelie Torgersen 39.1 18.7 181
#> 2 Adelie Torgersen 39.5 17.4 186
#> 3 Adelie Torgersen 40.3 18 195
#> 4 Adelie Torgersen NA NA NA
#> 5 Adelie Torgersen 36.7 19.3 193
#> 6 Adelie Torgersen 39.3 20.6 190
#> # ℹ 46 more rows
#> # ℹ 3 more variables: body_mass_g <dbl>, sex <chr>, year <dbl>或者,你可以使用 excel_sheets() 来获取 Excel 电子表格中所有工作表的信息,然后读取你感兴趣的一个或多个。
excel_sheets("data/penguins.xlsx")
#> [1] "Torgersen Island" "Biscoe Island" "Dream Island"一旦你知道了工作表的名称,你就可以用 read_excel() 单独读取它们。
penguins_biscoe <- read_excel("data/penguins.xlsx", sheet = "Biscoe Island", na = "NA")
penguins_dream <- read_excel("data/penguins.xlsx", sheet = "Dream Island", na = "NA")在这种情况下,完整的企鹅数据集分布在电子表格的三个工作表中。每个工作表有相同的列数,但行数不同。
我们可以用 bind_rows() 将它们合并在一起。
penguins <- bind_rows(penguins_torgersen, penguins_biscoe, penguins_dream)
penguins
#> # A tibble: 344 × 8
#> species island bill_length_mm bill_depth_mm flipper_length_mm
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Adelie Torgersen 39.1 18.7 181
#> 2 Adelie Torgersen 39.5 17.4 186
#> 3 Adelie Torgersen 40.3 18 195
#> 4 Adelie Torgersen NA NA NA
#> 5 Adelie Torgersen 36.7 19.3 193
#> 6 Adelie Torgersen 39.3 20.6 190
#> # ℹ 338 more rows
#> # ℹ 3 more variables: body_mass_g <dbl>, sex <chr>, year <dbl>在 Chapter 26 中,我们将讨论如何用不重复的代码来完成这类任务。
20.2.5 读取部分工作表
由于许多人使用 Excel 电子表格进行展示和数据存储,因此在电子表格中发现不属于你想读入 R 的数据的单元格条目是相当普遍的。Figure 20.3 展示了这样一个电子表格:在工作表的中间看起来像一个数据框,但在数据上方和下方有无关的文本。
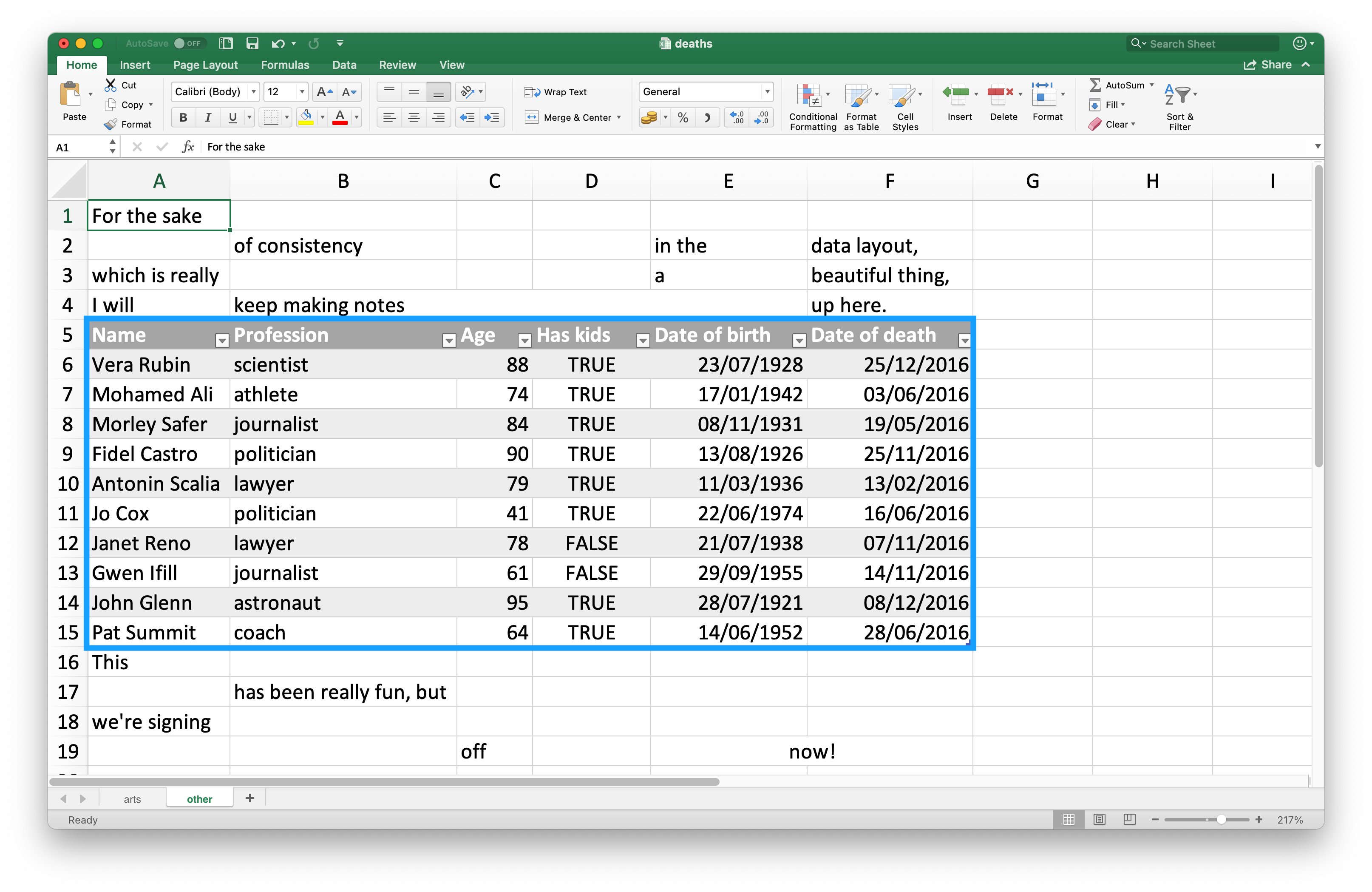
这个电子表格是 readxl 包中提供的示例电子表格之一。你可以使用 readxl_example() 函数在你系统上该包安装的目录中找到这个电子表格。这个函数返回电子表格的路径,你可以像往常一样在 read_excel() 中使用它。
deaths_path <- readxl_example("deaths.xlsx")
deaths <- read_excel(deaths_path)
#> New names:
#> • `` -> `...2`
#> • `` -> `...3`
#> • `` -> `...4`
#> • `` -> `...5`
#> • `` -> `...6`
deaths
#> # A tibble: 18 × 6
#> `Lots of people` ...2 ...3 ...4 ...5 ...6
#> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 simply cannot resi… <NA> <NA> <NA> <NA> some notes
#> 2 at the top <NA> of their spreadsh…
#> 3 or merging <NA> <NA> <NA> cells
#> 4 Name Profession Age Has kids Date of birth Date of death
#> 5 David Bowie musician 69 TRUE 17175 42379
#> 6 Carrie Fisher actor 60 TRUE 20749 42731
#> # ℹ 12 more rows顶部三行和底部四行不属于数据框。可以使用 skip 和 n_max 参数来消除这些多余的行,但我们建议使用单元格范围。在 Excel 中,左上角的单元格是 A1。当你向右移动列时,单元格标签会沿着字母表向下移动,即 B1、C1 等。当你向下移动一列时,单元格标签中的数字会增加,即 A2、A3 等。
这里我们想要读入的数据从单元格 A5 开始,到单元格 F15 结束。在电子表格表示法中,这是 A5:F15,我们将其提供给 range 参数:
read_excel(deaths_path, range = "A5:F15")
#> # A tibble: 10 × 6
#> Name Profession Age `Has kids` `Date of birth`
#> <chr> <chr> <dbl> <lgl> <dttm>
#> 1 David Bowie musician 69 TRUE 1947-01-08 00:00:00
#> 2 Carrie Fisher actor 60 TRUE 1956-10-21 00:00:00
#> 3 Chuck Berry musician 90 TRUE 1926-10-18 00:00:00
#> 4 Bill Paxton actor 61 TRUE 1955-05-17 00:00:00
#> 5 Prince musician 57 TRUE 1958-06-07 00:00:00
#> 6 Alan Rickman actor 69 FALSE 1946-02-21 00:00:00
#> # ℹ 4 more rows
#> # ℹ 1 more variable: `Date of death` <dttm>20.2.6 数据类型
在 CSV 文件中,所有值都是字符串。这并不特别忠实于数据,但很简单:一切都是字符串。
Excel 电子表格中的底层数据更复杂。一个单元格可以是以下四种类型之一:
布尔值,如
TRUE、FALSE或NA。数字,如 “10” 或 “10.5”。
日期时间,也可以包含时间,如 “11/1/21” 或 “11/1/21 3:00 PM”。
文本字符串,如 “ten”。
处理电子表格数据时,重要的是要记住,底层数据可能与你在单元格中看到的非常不同。例如,Excel 没有整数的概念。所有数字都存储为浮点数,但你可以选择以可自定义的小数位数来显示数据。同样,日期实际上是作为数字存储的,具体来说是从 1970 年 1 月 1 日以来的秒数。你可以通过在 Excel 中应用格式来自定义日期的显示方式。令人困惑的是,也可能有一个看起来像数字但实际上是字符串的东西(例如,在 Excel 单元格中输入 '10)。
这些底层数据存储方式与显示方式之间的差异,在数据加载到 R 时可能会导致意外。默认情况下,readxl 会猜测给定列的数据类型。一个推荐的工作流程是让 readxl 猜测列类型,确认你对猜测的列类型满意,如果不满意,则返回并重新导入,并指定 col_types,如 Section 20.2.3 所示。
另一个挑战是当你的 Excel 电子表格中的一列混合了这些类型时,例如,一些单元格是数值型,一些是文本,一些是日期。在将数据导入 R 时,readxl 必须做出一些决定。在这些情况下,你可以将该列的类型设置为 "list",这会将该列加载为一个长度为 1 的向量列表,其中列表的每个元素的类型都会被猜测。
有时数据以更奇特的方式存储,比如单元格背景的颜色,或者文本是否加粗。在这种情况下,你可能会发现 tidyxl 包 很有用。有关处理来自 Excel 的非表格数据的策略,请参见 https://nacnudus.github.io/spreadsheet-munging-strategies/。
20.2.7 写入 Excel
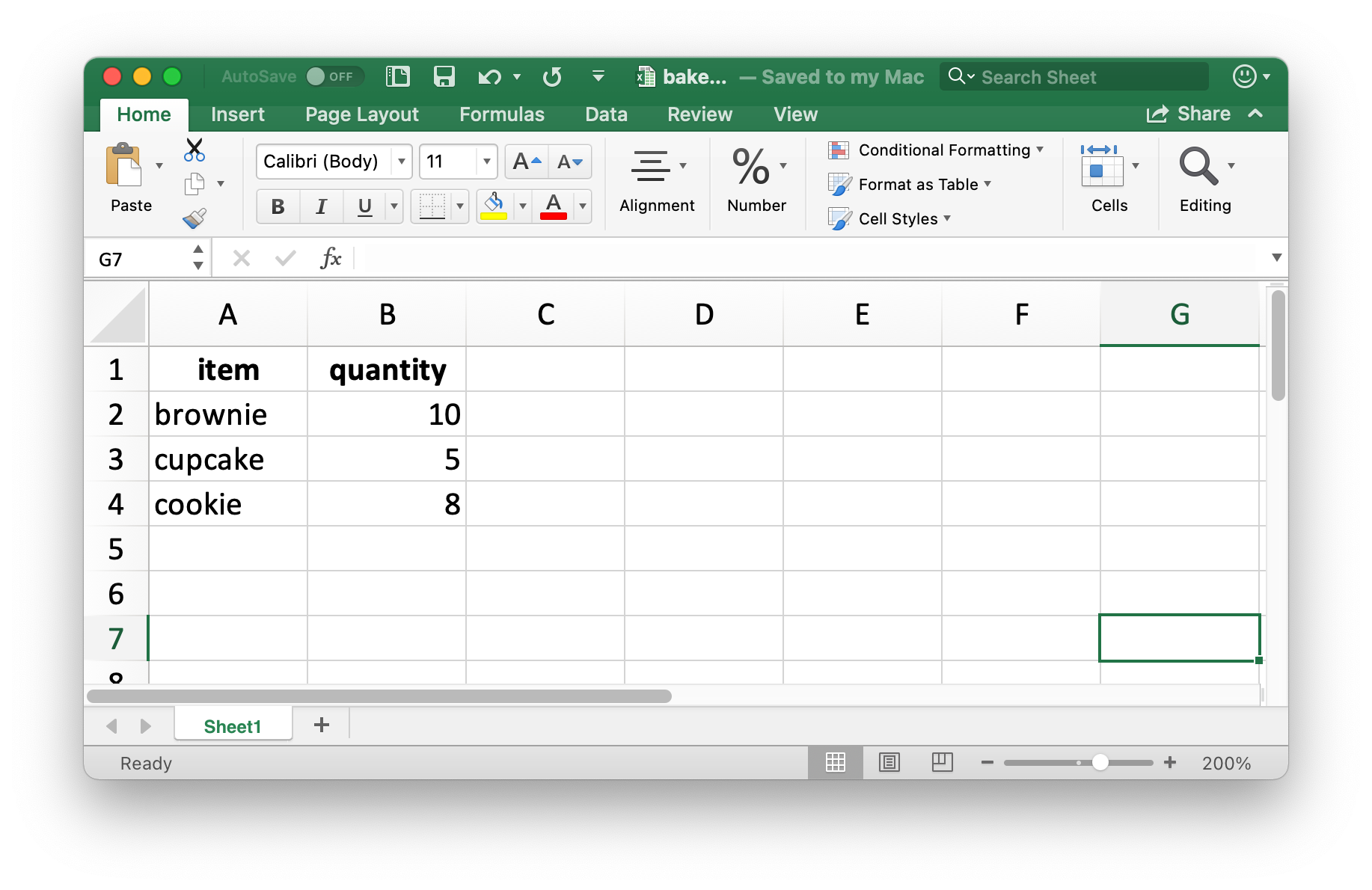
让我们创建一个小的数据框,然后可以把它写出去。注意 item 是一个因子,quantity 是一个整数。
你可以使用 writexl 包 中的 write_xlsx() 函数将数据写回到磁盘上的 Excel 文件中:
write_xlsx(bake_sale, path = "data/bake-sale.xlsx")Figure 20.4 展示了数据在 Excel 中的样子。注意列名被包含并加粗了。可以通过将 col_names 和 format_headers 参数设置为 FALSE 来关闭这些功能。
就像从 CSV 读取一样,当我们再次读入数据时,关于数据类型的信息会丢失。这也使得 Excel 文件不适合用于缓存中间结果。有关替代方案,请参见 Section 7.5。
read_excel("data/bake-sale.xlsx")
#> # A tibble: 3 × 2
#> item quantity
#> <chr> <dbl>
#> 1 brownie 10
#> 2 cupcake 5
#> 3 cookie 820.2.8 格式化输出
writexl 包是一个用于写入简单 Excel 电子表格的轻量级解决方案,但如果你对额外的功能感兴趣,比如写入电子表格中的工作表和设置样式,你会想使用 openxlsx 包。我们在这里不会详细介绍使用这个包的细节,但我们建议阅读 https://ycphs.github.io/openxlsx/articles/Formatting.html,那里有关于用 openxlsx 从 R 写入 Excel 的数据的进一步格式化功能的广泛讨论。
注意,这个包不是 tidyverse 的一部分,所以函数和工作流程可能会感觉不熟悉。例如,函数名是驼峰式命名法 (camelCase),多个函数不能用管道符组合,并且参数的顺序可能与 tidyverse 中的不同。然而,这没关系。随着你的 R 学习和使用扩展到本书之外,你会遇到各种 R 包中使用的许多不同风格,你可能会用它们来在 R 中完成特定的目标。熟悉一个新包的编码风格的一个好方法是运行函数文档中提供的示例,以感受其语法和输出格式,以及阅读包可能附带的任何小品文 (vignettes)。
20.2.9 练习
-
在一个 Excel 文件中,创建以下数据集并将其保存为
survey.xlsx。或者,你可以从这里下载 Excel 文件。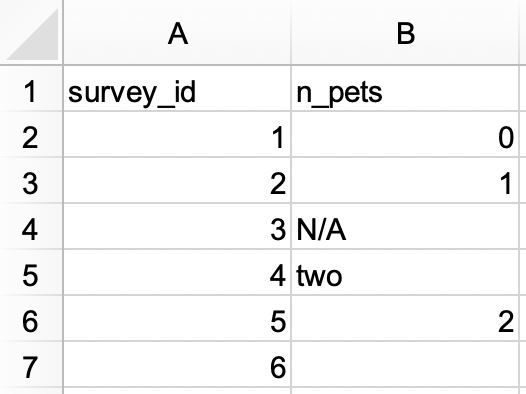
然后,将其读入 R,将
survey_id作为字符变量,n_pets作为数值变量。#> # A tibble: 6 × 2 #> survey_id n_pets #> <chr> <dbl> #> 1 1 0 #> 2 2 1 #> 3 3 NA #> 4 4 2 #> 5 5 2 #> 6 6 NA -
在另一个 Excel 文件中,创建以下数据集并将其保存为
roster.xlsx。或者,你可以从这里下载 Excel 文件。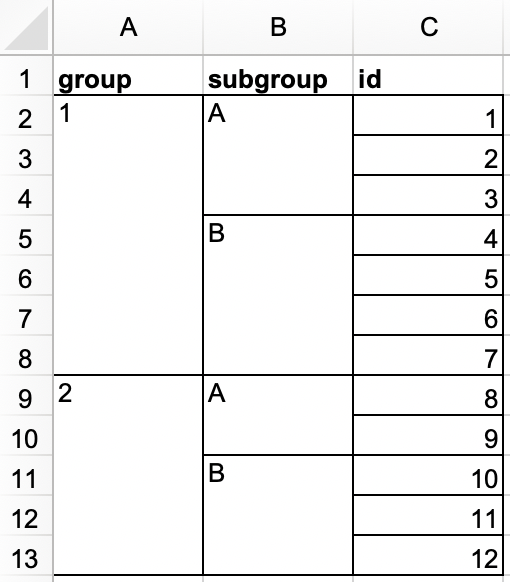
然后,将其读入 R。结果数据框应命名为
roster,并应如下所示。#> # A tibble: 12 × 3 #> group subgroup id #> <dbl> <chr> <dbl> #> 1 1 A 1 #> 2 1 A 2 #> 3 1 A 3 #> 4 1 B 4 #> 5 1 B 5 #> 6 1 B 6 #> 7 1 B 7 #> 8 2 A 8 #> 9 2 A 9 #> 10 2 B 10 #> 11 2 B 11 #> 12 2 B 12 -
在一个新的 Excel 文件中,创建以下数据集并将其保存为
sales.xlsx。或者,你可以从这里下载 Excel 文件。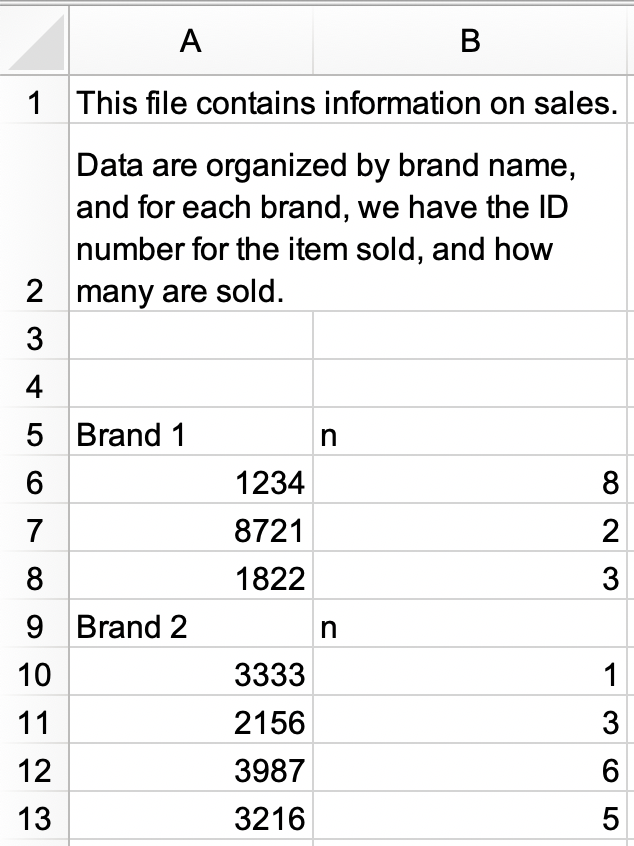
- 读入
sales.xlsx并保存为sales。数据框应如下所示,列名为id和n,有 9 行。
#> # A tibble: 9 × 2 #> id n #> <chr> <chr> #> 1 Brand 1 n #> 2 1234 8 #> 3 8721 2 #> 4 1822 3 #> 5 Brand 2 n #> 6 3333 1 #> 7 2156 3 #> 8 3987 6 #> 9 3216 5- 进一步修改
sales,使其成为以下具有三列(brand、id和n)和 7 行数据的整洁格式。注意id和n是数值型,brand是字符变量。
#> # A tibble: 7 × 3 #> brand id n #> <chr> <dbl> <dbl> #> 1 Brand 1 1234 8 #> 2 Brand 1 8721 2 #> 3 Brand 1 1822 3 #> 4 Brand 2 3333 1 #> 5 Brand 2 2156 3 #> 6 Brand 2 3987 6 #> 7 Brand 2 3216 5 - 读入
重新创建
bake_sale数据框,使用 openxlsx 包中的write.xlsx()函数将其写出到一个 Excel 文件中。在 Chapter 7 中,你学习了
janitor::clean_names()函数,可以将列名转换为蛇形命名法 (snake case)。读入我们本节前面介绍的students.xlsx文件,并使用此函数来“清理”列名。如果你尝试用
read_xls()读取一个扩展名为.xlsx的文件会发生什么?
20.3 谷歌表格
谷歌表格 (Google Sheets) 是另一个广泛使用的电子表格程序。它是免费且基于网络的。就像 Excel 一样,在谷歌表格中,数据在电子表格文件中的工作表 (worksheets) 里进行组织。
20.3.1 前提条件
本节也将重点介绍电子表格,但这次你将使用 googlesheets4 包从谷歌表格中加载数据。这个包同样不是 tidyverse 的核心包,你需要显式地加载它。
关于包名的一个快速说明:googlesheets4 使用了 Sheets API v4 来提供一个 R 接口到谷歌表格,因此得名。
20.3.2 入门
googlesheets4 包的主要函数是 read_sheet(),它从一个 URL 或文件 ID 读取一个谷歌表格。这个函数还有一个别名 range_read()。
你也可以用 gs4_create() 创建一个全新的表格,或者用 sheet_write() 及其系列函数写入一个现有的表格。
在本节中,我们将使用与 Excel 部分相同的数据集,以突出从 Excel 和谷歌表格读取数据的工作流程之间的相似点和不同点。readxl 和 googlesheets4 包都被设计为模仿 readr 包的功能,后者提供了你在 Chapter 7 中见过的 read_csv() 函数。因此,许多任务可以通过简单地将 read_excel() 替换为 read_sheet() 来完成。然而,你也会看到 Excel 和谷歌表格的行为并不完全相同,因此其他任务可能需要对函数调用进行进一步的更新。
20.3.3 读取谷歌表格
Figure 20.5 展示了我们即将读入 R 的电子表格在谷歌表格中的样子。这与 Figure 20.1 中的数据集相同,只是它存储在谷歌表格中而不是 Excel 中。
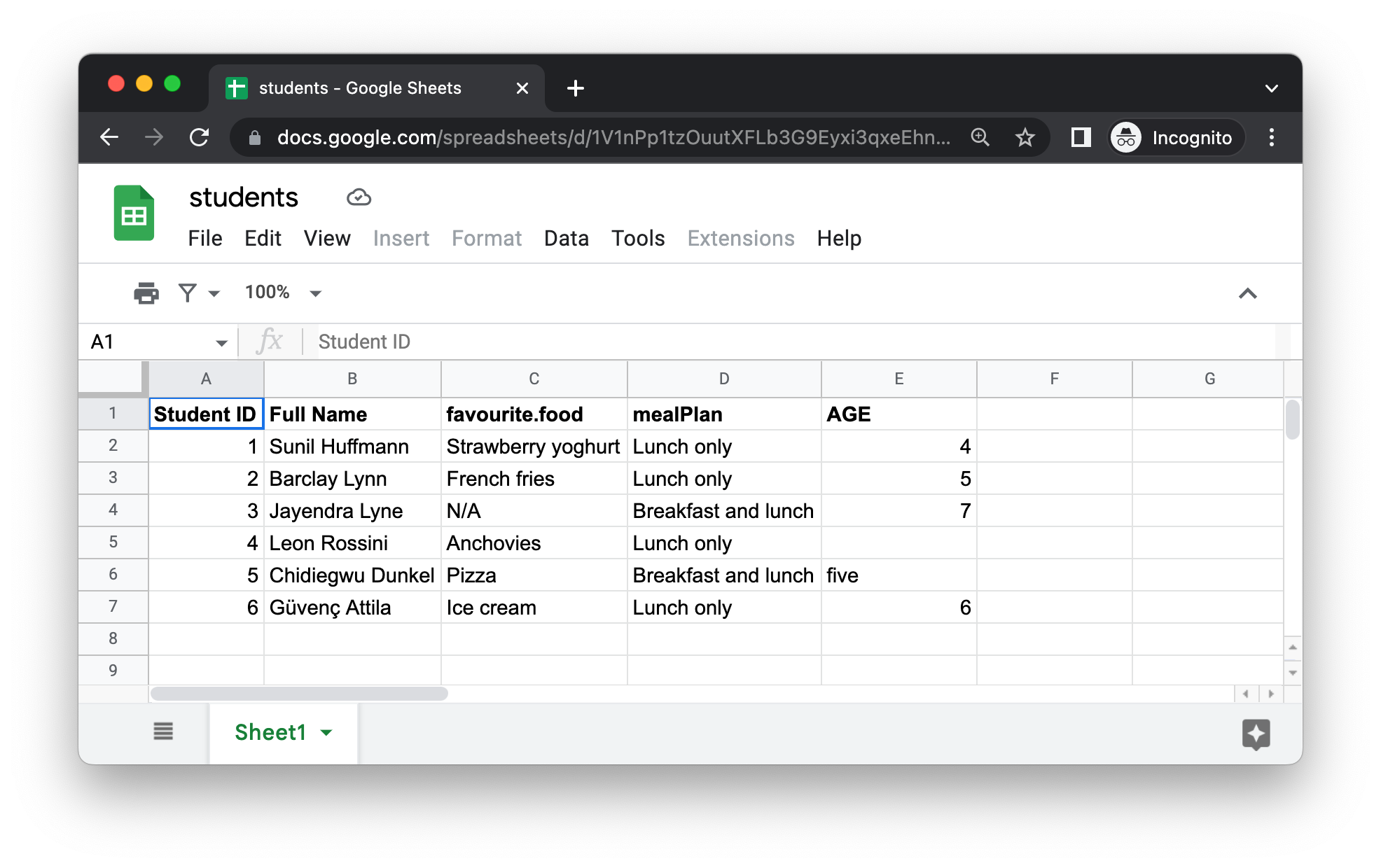
read_sheet() 的第一个参数是要读取的文件的 URL,它返回一个 tibble: https://docs.google.com/spreadsheets/d/1V1nPp1tzOuutXFLb3G9Eyxi3qxeEhnOXUzL5_BcCQ0w。 这些 URL 不好用,所以你通常会想通过其 ID 来识别一个表格。
students_sheet_id <- "1V1nPp1tzOuutXFLb3G9Eyxi3qxeEhnOXUzL5_BcCQ0w"
students <- read_sheet(students_sheet_id)
#> ✔ Reading from students.
#> ✔ Range Sheet1.
students
#> # A tibble: 6 × 5
#> `Student ID` `Full Name` favourite.food mealPlan AGE
#> <dbl> <chr> <chr> <chr> <list>
#> 1 1 Sunil Huffmann Strawberry yoghurt Lunch only <dbl>
#> 2 2 Barclay Lynn French fries Lunch only <dbl>
#> 3 3 Jayendra Lyne N/A Breakfast and lunch <dbl>
#> 4 4 Leon Rossini Anchovies Lunch only <NULL>
#> 5 5 Chidiegwu Dunkel Pizza Breakfast and lunch <chr>
#> 6 6 Güvenç Attila Ice cream Lunch only <dbl>就像我们对 read_excel() 做的那样,我们可以向 read_sheet() 提供列名、NA 字符串和列类型。
students <- read_sheet(
students_sheet_id,
col_names = c("student_id", "full_name", "favourite_food", "meal_plan", "age"),
skip = 1,
na = c("", "N/A"),
col_types = "dcccc"
)
#> ✔ Reading from students.
#> ✔ Range 2:10000000.
students
#> # A tibble: 6 × 5
#> student_id full_name favourite_food meal_plan age
#> <dbl> <chr> <chr> <chr> <chr>
#> 1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4
#> 2 2 Barclay Lynn French fries Lunch only 5
#> 3 3 Jayendra Lyne <NA> Breakfast and lunch 7
#> 4 4 Leon Rossini Anchovies Lunch only <NA>
#> 5 5 Chidiegwu Dunkel Pizza Breakfast and lunch five
#> 6 6 Güvenç Attila Ice cream Lunch only 6注意,我们在这里定义列类型的方式略有不同,使用了短代码。例如,“dcccc” 代表 “double, character, character, character, character”。
也可以从谷歌表格中读取单个工作表。让我们从企鹅谷歌表格中读取 “Torgersen Island” 工作表:
penguins_sheet_id <- "1aFu8lnD_g0yjF5O-K6SFgSEWiHPpgvFCF0NY9D6LXnY"
read_sheet(penguins_sheet_id, sheet = "Torgersen Island")
#> ✔ Reading from penguins.
#> ✔ Range ''Torgersen Island''.
#> # A tibble: 52 × 8
#> species island bill_length_mm bill_depth_mm flipper_length_mm
#> <chr> <chr> <list> <list> <list>
#> 1 Adelie Torgersen <dbl [1]> <dbl [1]> <dbl [1]>
#> 2 Adelie Torgersen <dbl [1]> <dbl [1]> <dbl [1]>
#> 3 Adelie Torgersen <dbl [1]> <dbl [1]> <dbl [1]>
#> 4 Adelie Torgersen <chr [1]> <chr [1]> <chr [1]>
#> 5 Adelie Torgersen <dbl [1]> <dbl [1]> <dbl [1]>
#> 6 Adelie Torgersen <dbl [1]> <dbl [1]> <dbl [1]>
#> # ℹ 46 more rows
#> # ℹ 3 more variables: body_mass_g <list>, sex <chr>, year <dbl>你可以使用 sheet_names() 获取一个谷歌表格中所有工作表的列表:
sheet_names(penguins_sheet_id)
#> [1] "Torgersen Island" "Biscoe Island" "Dream Island"最后,就像使用 read_excel() 一样,我们可以通过在 read_sheet() 中定义一个 range 来读取谷歌表格的一部分。注意,我们下面也使用了 gs4_example() 函数来定位 googlesheets4 包附带的一个示例谷歌表格。
deaths_url <- gs4_example("deaths")
deaths <- read_sheet(deaths_url, range = "A5:F15")
#> ✔ Reading from deaths.
#> ✔ Range A5:F15.
deaths
#> # A tibble: 10 × 6
#> Name Profession Age `Has kids` `Date of birth`
#> <chr> <chr> <dbl> <lgl> <dttm>
#> 1 David Bowie musician 69 TRUE 1947-01-08 00:00:00
#> 2 Carrie Fisher actor 60 TRUE 1956-10-21 00:00:00
#> 3 Chuck Berry musician 90 TRUE 1926-10-18 00:00:00
#> 4 Bill Paxton actor 61 TRUE 1955-05-17 00:00:00
#> 5 Prince musician 57 TRUE 1958-06-07 00:00:00
#> 6 Alan Rickman actor 69 FALSE 1946-02-21 00:00:00
#> # ℹ 4 more rows
#> # ℹ 1 more variable: `Date of death` <dttm>20.3.4 写入谷歌表格
你可以使用 write_sheet() 从 R 写入谷歌表格。第一个参数是要写入的数据框,第二个参数是要写入的谷歌表格的名称(或其他标识符):
write_sheet(bake_sale, ss = "bake-sale")如果你想将数据写入谷歌表格中的特定(工作)表,你也可以使用 sheet 参数来指定。
write_sheet(bake_sale, ss = "bake-sale", sheet = "Sales")20.3.5 身份验证
虽然你可以从未经身份验证的公共谷歌表格中读取数据,并使用 gs4_deauth(),但读取私有表格或写入表格需要进行身份验证,以便 googlesheets4 可以查看和管理你的谷歌表格。
当你尝试读取一个需要身份验证的表格时,googlesheets4 会将你引导到一个网页浏览器,提示你登录你的谷歌账户并授权其代表你操作谷歌表格。然而,如果你想指定一个特定的谷歌账户、身份验证范围等,你可以使用 gs4_auth() 来实现,例如,gs4_auth(email = "mine@example.com"),这将强制使用与特定电子邮件关联的令牌。有关进一步的身份验证细节,我们建议阅读 googlesheets4 的 auth 小品文文档:https://googlesheets4.tidyverse.org/articles/auth.html。
20.3.6 练习
从 Excel 和谷歌表格中读取本章早些时候的
students数据集,不向read_excel()和read_sheet()函数提供任何额外参数。结果在 R 中的数据框完全相同吗?如果不是,它们有何不同?从 https://pos.it/r4ds-survey 读取名为 survey 的谷歌表格,将
survey_id作为字符变量,n_pets作为数值变量。-
从 https://pos.it/r4ds-roster 读取名为 roster 的谷歌表格。结果数据框应命名为
roster,并应如下所示。#> # A tibble: 12 × 3 #> group subgroup id #> <dbl> <chr> <dbl> #> 1 1 A 1 #> 2 1 A 2 #> 3 1 A 3 #> 4 1 B 4 #> 5 1 B 5 #> 6 1 B 6 #> 7 1 B 7 #> 8 2 A 8 #> 9 2 A 9 #> 10 2 B 10 #> 11 2 B 11 #> 12 2 B 12
20.4 总结
Microsoft Excel 和谷歌表格是两种最流行的电子表格系统。能够直接从 R 中与存储在 Excel 和谷歌表格文件中的数据进行交互是一项超能力!在本章中,你学习了如何使用 readxl 包中的 read_excel() 从 Excel 的电子表格中读取数据到 R,以及如何使用 googlesheets4 包中的 read_sheet() 从谷歌表格中读取数据。这些函数的工作方式非常相似,并且有类似的参数用于指定列名、NA 字符串、在读取文件时跳过顶部的行等。此外,这两个函数都使得可以从一个电子表格中读取单个工作表。
另一方面,写入 Excel 文件需要一个不同的包和函数 (writexl::write_xlsx()),而你可以使用 googlesheets4 包中的 write_sheet() 来写入谷歌表格。
在下一章中,你将学习一个不同的数据源以及如何从该源读取数据到 R:数据库。