19 连接
19.1 引言
数据分析很少只涉及单个数据框。通常你会有多个数据框,并且必须将它们连接 (join) 在一起以回答你感兴趣的问题。本章将向你介绍两种重要的连接类型:
- 变连接 (Mutating joins),它将一个数据框中的匹配观测值的新变量添加到另一个数据框中。
- 过滤连接 (Filtering joins),它根据一个数据框中的观测值是否与另一个数据框中的观测值匹配来过滤该数据框中的观测值。
我们将首先讨论键 (keys),即用于在连接中连接一对数据框的变量。我们将通过检查 nycflights13 包中数据集的键来巩固理论,然后利用这些知识开始连接数据框。接下来,我们将讨论连接的工作原理,重点关注它们对行的操作。最后,我们将讨论非等值连接 (non-equi joins),这是一类连接,它提供了一种比默认的相等关系更灵活的键匹配方式。
19.1.1 前提条件
在本章中,我们将使用 dplyr 中的连接函数来探索 nycflights13 中的五个相关数据集。
19.2 键
要理解连接,你首先需要了解两个表如何通过每个表内的一对键连接起来。在本节中,你将学习两种类型的键,并在 nycflights13 包的数据集中看到这两种键的示例。你还将学习如何检查你的键是否有效,以及当你的表缺少键时该怎么办。
19.2.1 主键和外键
每个连接都涉及一对键:一个主键和一个外键。 主键 (primary key) 是一个或一组唯一标识每个观测值的变量。当需要多个变量时,该键称为复合键 (compound key)。例如,在 nycflights13 中:
-
airlines记录了关于每家航空公司的两条数据:其航空公司代码和全名。你可以用它的两个字母的航空公司代码来识别一家航空公司,这使得carrier成为主键。airlines #> # A tibble: 16 × 2 #> carrier name #> <chr> <chr> #> 1 9E Endeavor Air Inc. #> 2 AA American Airlines Inc. #> 3 AS Alaska Airlines Inc. #> 4 B6 JetBlue Airways #> 5 DL Delta Air Lines Inc. #> 6 EV ExpressJet Airlines Inc. #> # ℹ 10 more rows -
airports记录了关于每个机场的数据。你可以用它的三个字母的机场代码来识别每个机场,这使得faa成为主键。airports #> # A tibble: 1,458 × 8 #> faa name lat lon alt tz dst #> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr> #> 1 04G Lansdowne Airport 41.1 -80.6 1044 -5 A #> 2 06A Moton Field Municipal Airport 32.5 -85.7 264 -6 A #> 3 06C Schaumburg Regional 42.0 -88.1 801 -6 A #> 4 06N Randall Airport 41.4 -74.4 523 -5 A #> 5 09J Jekyll Island Airport 31.1 -81.4 11 -5 A #> 6 0A9 Elizabethton Municipal Airpo… 36.4 -82.2 1593 -5 A #> # ℹ 1,452 more rows #> # ℹ 1 more variable: tzone <chr> -
planes记录了关于每架飞机的数据。你可以用它的尾号来识别一架飞机,这使得tailnum成为主键。planes #> # A tibble: 3,322 × 9 #> tailnum year type manufacturer model engines #> <chr> <int> <chr> <chr> <chr> <int> #> 1 N10156 2004 Fixed wing multi… EMBRAER EMB-145XR 2 #> 2 N102UW 1998 Fixed wing multi… AIRBUS INDUSTR… A320-214 2 #> 3 N103US 1999 Fixed wing multi… AIRBUS INDUSTR… A320-214 2 #> 4 N104UW 1999 Fixed wing multi… AIRBUS INDUSTR… A320-214 2 #> 5 N10575 2002 Fixed wing multi… EMBRAER EMB-145LR 2 #> 6 N105UW 1999 Fixed wing multi… AIRBUS INDUSTR… A320-214 2 #> # ℹ 3,316 more rows #> # ℹ 3 more variables: seats <int>, speed <int>, engine <chr> -
weather记录了始发机场的天气数据。你可以通过位置和时间的组合来识别每个观测值,这使得origin和time_hour成为复合主键。weather #> # A tibble: 26,115 × 15 #> origin year month day hour temp dewp humid wind_dir #> <chr> <int> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> #> 1 EWR 2013 1 1 1 39.0 26.1 59.4 270 #> 2 EWR 2013 1 1 2 39.0 27.0 61.6 250 #> 3 EWR 2013 1 1 3 39.0 28.0 64.4 240 #> 4 EWR 2013 1 1 4 39.9 28.0 62.2 250 #> 5 EWR 2013 1 1 5 39.0 28.0 64.4 260 #> 6 EWR 2013 1 1 6 37.9 28.0 67.2 240 #> # ℹ 26,109 more rows #> # ℹ 6 more variables: wind_speed <dbl>, wind_gust <dbl>, …
外键 (foreign key) 是一个(或一组)与另一个表中的主键相对应的变量。例如:
-
flights$tailnum是一个外键,对应于主键planes$tailnum。 -
flights$carrier是一个外键,对应于主键airlines$carrier。 -
flights$origin是一个外键,对应于主键airports$faa。 -
flights$dest是一个外键,对应于主键airports$faa。 -
flights$origin-flights$time_hour是一个复合外键,对应于复合主键weather$origin-weather$time_hour。
这些关系在 Figure 19.1 中进行了可视化总结。
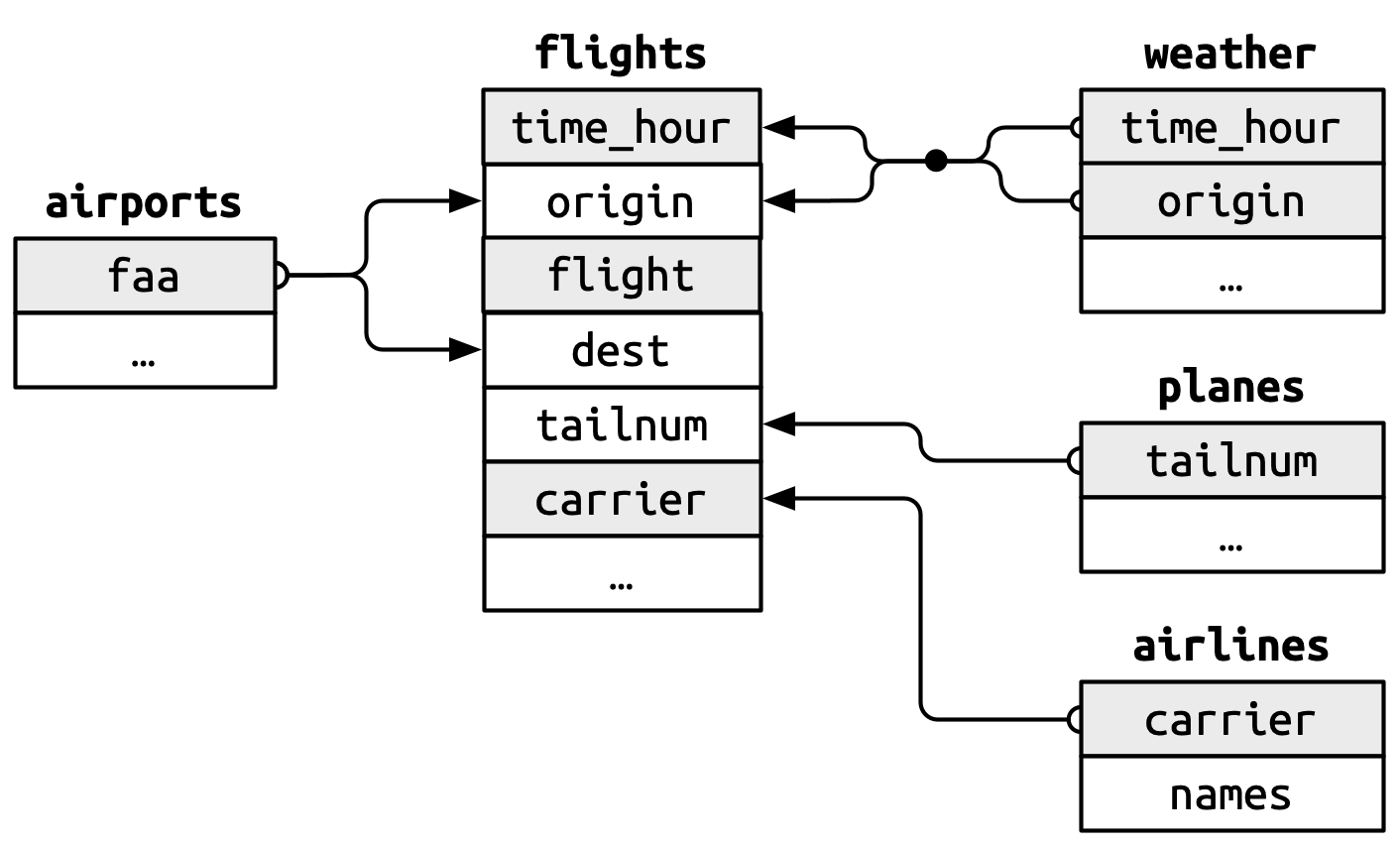
你会注意到这些键的设计中有一个很好的特性:主键和外键几乎总是有相同的名称,正如你稍后将看到的,这将使你的连接工作变得容易得多。同样值得注意的是相反的关系:几乎每个在多个表中使用的变量名在每个地方都有相同的含义。只有一个例外:在 flights 中 year 表示出发年份,在 planes 中表示制造年份。当我们开始实际连接表时,这将变得很重要。
19.2.2 检查主键
既然我们已经确定了每个表中的主键,一个好的做法是验证它们确实唯一地标识了每个观测值。一种方法是 count() 主键,并查找 n 大于 1 的条目。这表明 planes 和 weather 都看起来不错:
你还应该检查主键中是否有缺失值——如果一个值是缺失的,那么它就不能标识一个观测值!
planes |>
filter(is.na(tailnum))
#> # A tibble: 0 × 9
#> # ℹ 9 variables: tailnum <chr>, year <int>, type <chr>, manufacturer <chr>,
#> # model <chr>, engines <int>, seats <int>, speed <int>, engine <chr>
weather |>
filter(is.na(time_hour) | is.na(origin))
#> # A tibble: 0 × 15
#> # ℹ 15 variables: origin <chr>, year <int>, month <int>, day <int>,
#> # hour <int>, temp <dbl>, dewp <dbl>, humid <dbl>, wind_dir <dbl>, …19.2.3 代理键
到目前为止,我们还没有讨论 flights 的主键。它在这里不是非常重要,因为没有数据框使用它作为外键,但考虑它仍然是有用的,因为如果我们有某种方式向他人描述观测值,那么处理观测值会更容易。
经过一番思考和实验,我们确定有三个变量可以共同唯一地标识每个航班:
没有重复值是否自动使 time_hour-carrier-flight 成为一个主键?这当然是一个好的开始,但并不能保证它。例如,海拔和纬度是 airports 的一个好的主键吗?
通过海拔和纬度来识别一个机场显然是一个坏主意,而且总的来说,仅从数据本身不可能知道一个变量组合是否构成一个好的主键。但对于航班来说,time_hour、carrier 和 flight 的组合似乎是合理的,因为如果同一时间同一家航空公司有多个相同航班号的航班在空中,那对航空公司及其客户来说会非常混乱。
话虽如此,我们最好还是引入一个简单的数字代理键,使用行号:
flights2 <- flights |>
mutate(id = row_number(), .before = 1)
flights2
#> # A tibble: 336,776 × 20
#> id year month day dep_time sched_dep_time dep_delay arr_time
#> <int> <int> <int> <int> <int> <int> <dbl> <int>
#> 1 1 2013 1 1 517 515 2 830
#> 2 2 2013 1 1 533 529 4 850
#> 3 3 2013 1 1 542 540 2 923
#> 4 4 2013 1 1 544 545 -1 1004
#> 5 5 2013 1 1 554 600 -6 812
#> 6 6 2013 1 1 554 558 -4 740
#> # ℹ 336,770 more rows
#> # ℹ 12 more variables: sched_arr_time <int>, arr_delay <dbl>, …代理键在与他人交流时特别有用:告诉某人查看航班 2001 比告诉他们查看 2013 年 1 月 3 日上午 9 点出发的 UA430 要容易得多。
19.2.4 练习
我们在 Figure 19.1 中忘记绘制
weather和airports之间的关系了。这个关系是什么?它应该如何在图中显示?weather只包含纽约市三个始发机场的信息。如果它包含了美国所有机场的天气记录,它会与flights建立什么额外的连接?year、month、day、hour和origin变量几乎构成了weather的一个复合键,但有一个小时有重复的观测值。你能找出那个小时有什么特别之处吗?我们知道一年中的某些日子是特殊的,飞行的人比平时少(例如,平安夜和圣诞节)。你如何将这些数据表示为一个数据框?主键会是什么?它将如何与现有的数据框连接?
在 Lahman 包中,绘制一个图表来说明
Batting、People和Salaries数据框之间的连接。再绘制一个图表来显示People、Managers和AwardsManagers之间的关系。你将如何描述Batting、Pitching和Fielding数据框之间的关系?
19.3 基本连接
既然你已经了解了数据框如何通过键连接,我们就可以开始使用连接来更好地理解 flights 数据集了。dplyr 提供了六个连接函数:left_join()、inner_join()、right_join()、full_join()、semi_join() 和 anti_join()。它们都有相同的接口:它们接受一对数据框(x 和 y),并返回一个数据框。输出的行和列的顺序主要由 x 决定。
在本节中,你将学习如何使用一个变连接 left_join() 和两个过滤连接 semi_join() 和 anti_join()。在下一节中,你将确切地学习这些函数如何工作,以及剩下的 inner_join()、right_join() 和 full_join()。
19.3.1 变连接
变连接 (mutating join) 允许你组合两个数据框中的变量:它首先通过它们的键来匹配观测值,然后将一个数据框中的变量复制到另一个数据框中。像 mutate() 一样,连接函数在右侧添加变量,所以如果你的数据集有很多变量,你将看不到新的变量。对于这些例子,我们将通过创建一个只有六个变量的较窄的数据集来使其更容易看清发生了什么1:
flights2 <- flights |>
select(year, time_hour, origin, dest, tailnum, carrier)
flights2
#> # A tibble: 336,776 × 6
#> year time_hour origin dest tailnum carrier
#> <int> <dttm> <chr> <chr> <chr> <chr>
#> 1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA
#> 2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA
#> 3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA
#> 4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6
#> 5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL
#> 6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA
#> # ℹ 336,770 more rows有四种类型的变连接,但有一种你几乎总是会使用:left_join()。它很特别,因为输出将始终与 x(你正在连接的数据框)具有相同的行2。left_join() 的主要用途是添加额外的元数据。例如,我们可以使用 left_join() 将完整的航空公司名称添加到 flights2 数据中:
flights2 |>
left_join(airlines)
#> Joining with `by = join_by(carrier)`
#> # A tibble: 336,776 × 7
#> year time_hour origin dest tailnum carrier name
#> <int> <dttm> <chr> <chr> <chr> <chr> <chr>
#> 1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA United Air Lines In…
#> 2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA United Air Lines In…
#> 3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA American Airlines I…
#> 4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 JetBlue Airways
#> 5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL Delta Air Lines Inc.
#> 6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA United Air Lines In…
#> # ℹ 336,770 more rows或者我们可以找出每架飞机起飞时的温度和风速:
flights2 |>
left_join(weather |> select(origin, time_hour, temp, wind_speed))
#> Joining with `by = join_by(time_hour, origin)`
#> # A tibble: 336,776 × 8
#> year time_hour origin dest tailnum carrier temp wind_speed
#> <int> <dttm> <chr> <chr> <chr> <chr> <dbl> <dbl>
#> 1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA 39.0 12.7
#> 2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA 39.9 15.0
#> 3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA 39.0 15.0
#> 4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 39.0 15.0
#> 5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL 39.9 16.1
#> 6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA 39.0 12.7
#> # ℹ 336,770 more rows或者是什么尺寸的飞机在飞行:
flights2 |>
left_join(planes |> select(tailnum, type, engines, seats))
#> Joining with `by = join_by(tailnum)`
#> # A tibble: 336,776 × 9
#> year time_hour origin dest tailnum carrier type
#> <int> <dttm> <chr> <chr> <chr> <chr> <chr>
#> 1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA Fixed wing multi en…
#> 2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA Fixed wing multi en…
#> 3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA Fixed wing multi en…
#> 4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 Fixed wing multi en…
#> 5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL Fixed wing multi en…
#> 6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA Fixed wing multi en…
#> # ℹ 336,770 more rows
#> # ℹ 2 more variables: engines <int>, seats <int>当 left_join() 未能为 x 中的某一行找到匹配项时,它会用缺失值填充新变量。例如,没有关于尾号为 N3ALAA 的飞机的信息,所以 type、engines 和 seats 将是缺失的:
flights2 |>
filter(tailnum == "N3ALAA") |>
left_join(planes |> select(tailnum, type, engines, seats))
#> Joining with `by = join_by(tailnum)`
#> # A tibble: 63 × 9
#> year time_hour origin dest tailnum carrier type engines seats
#> <int> <dttm> <chr> <chr> <chr> <chr> <chr> <int> <int>
#> 1 2013 2013-01-01 06:00:00 LGA ORD N3ALAA AA <NA> NA NA
#> 2 2013 2013-01-02 18:00:00 LGA ORD N3ALAA AA <NA> NA NA
#> 3 2013 2013-01-03 06:00:00 LGA ORD N3ALAA AA <NA> NA NA
#> 4 2013 2013-01-07 19:00:00 LGA ORD N3ALAA AA <NA> NA NA
#> 5 2013 2013-01-08 17:00:00 JFK ORD N3ALAA AA <NA> NA NA
#> 6 2013 2013-01-16 06:00:00 LGA ORD N3ALAA AA <NA> NA NA
#> # ℹ 57 more rows我们将在本章的其余部分几次回到这个问题。
19.3.2 指定连接键
默认情况下,left_join() 将使用同时出现在两个数据框中的所有变量作为连接键,这被称为自然 (natural) 连接。这是一个有用的启发式方法,但它并不总是有效。例如,如果我们尝试将 flights2 与完整的 planes 数据集连接会发生什么?
flights2 |>
left_join(planes)
#> Joining with `by = join_by(year, tailnum)`
#> # A tibble: 336,776 × 13
#> year time_hour origin dest tailnum carrier type manufacturer
#> <int> <dttm> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA <NA> <NA>
#> 2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA <NA> <NA>
#> 3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA <NA> <NA>
#> 4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 <NA> <NA>
#> 5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL <NA> <NA>
#> 6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA <NA> <NA>
#> # ℹ 336,770 more rows
#> # ℹ 5 more variables: model <chr>, engines <int>, seats <int>, …我们得到了很多缺失的匹配,因为我们的连接正在尝试使用 tailnum 和 year 作为复合键。flights 和 planes 都有一个 year 列,但它们的含义不同:flights$year 是航班发生的年份,而 planes$year 是飞机制造的年份。我们只想在 tailnum上连接,所以我们需要使用 join_by() 提供一个明确的规范:
flights2 |>
left_join(planes, join_by(tailnum))
#> # A tibble: 336,776 × 14
#> year.x time_hour origin dest tailnum carrier year.y
#> <int> <dttm> <chr> <chr> <chr> <chr> <int>
#> 1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA 1999
#> 2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA 1998
#> 3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA 1990
#> 4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 2012
#> 5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL 1991
#> 6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA 2012
#> # ℹ 336,770 more rows
#> # ℹ 7 more variables: type <chr>, manufacturer <chr>, model <chr>, …请注意,year 变量在输出中通过后缀(year.x 和 year.y)进行了区分,这告诉你变量是来自 x 参数还是 y 参数。你可以使用 suffix 参数覆盖默认的后缀。
join_by(tailnum) 是 join_by(tailnum == tailnum) 的简写。了解这种更完整的形式很重要,原因有二。首先,它描述了两个表之间的关系:键必须相等。这就是为什么这种类型的连接通常被称为等值连接 (equi join)。你将在 Section 19.5 中学习非等值连接。
其次,这是你在每个表中指定不同连接键的方式。例如,有两种方法可以连接 flight2 和 airports 表:通过 dest 或 origin:
flights2 |>
left_join(airports, join_by(dest == faa))
#> # A tibble: 336,776 × 13
#> year time_hour origin dest tailnum carrier name
#> <int> <dttm> <chr> <chr> <chr> <chr> <chr>
#> 1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA George Bush Interco…
#> 2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA George Bush Interco…
#> 3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA Miami Intl
#> 4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 <NA>
#> 5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL Hartsfield Jackson …
#> 6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA Chicago Ohare Intl
#> # ℹ 336,770 more rows
#> # ℹ 6 more variables: lat <dbl>, lon <dbl>, alt <dbl>, tz <dbl>, …
flights2 |>
left_join(airports, join_by(origin == faa))
#> # A tibble: 336,776 × 13
#> year time_hour origin dest tailnum carrier name
#> <int> <dttm> <chr> <chr> <chr> <chr> <chr>
#> 1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA Newark Liberty Intl
#> 2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA La Guardia
#> 3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA John F Kennedy Intl
#> 4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 John F Kennedy Intl
#> 5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL La Guardia
#> 6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA Newark Liberty Intl
#> # ℹ 336,770 more rows
#> # ℹ 6 more variables: lat <dbl>, lon <dbl>, alt <dbl>, tz <dbl>, …在旧代码中,你可能会看到一种不同的指定连接键的方式,使用一个字符向量:
-
by = "x"对应于join_by(x)。 -
by = c("a" = "x")对应于join_by(a == x)。
既然 join_by() 已经存在,我们更喜欢使用它,因为它提供了更清晰和更灵活的规范。
inner_join()、right_join()、full_join() 的接口与 left_join() 相同。区别在于它们保留哪些行:左连接保留 x 中的所有行,右连接保留 y 中的所有行,全连接保留 x 或 y 中的所有行,而内连接只保留同时出现在 x 和 y 中的行。我们稍后会更详细地回到这些。
19.3.3 过滤连接
你可能猜到,过滤连接 (filtering join) 的主要作用是过滤行。有两种类型:半连接 (semi-joins) 和反连接 (anti-joins)。 半连接保留 x 中所有在 y 中有匹配的行。例如,我们可以使用半连接来过滤 airports 数据集,只显示始发机场:
airports |>
semi_join(flights2, join_by(faa == origin))
#> # A tibble: 3 × 8
#> faa name lat lon alt tz dst tzone
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
#> 1 EWR Newark Liberty Intl 40.7 -74.2 18 -5 A America/New_York
#> 2 JFK John F Kennedy Intl 40.6 -73.8 13 -5 A America/New_York
#> 3 LGA La Guardia 40.8 -73.9 22 -5 A America/New_York或者只显示目的地:
airports |>
semi_join(flights2, join_by(faa == dest))
#> # A tibble: 101 × 8
#> faa name lat lon alt tz dst tzone
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
#> 1 ABQ Albuquerque Internati… 35.0 -107. 5355 -7 A America/Denver
#> 2 ACK Nantucket Mem 41.3 -70.1 48 -5 A America/New_Yo…
#> 3 ALB Albany Intl 42.7 -73.8 285 -5 A America/New_Yo…
#> 4 ANC Ted Stevens Anchorage… 61.2 -150. 152 -9 A America/Anchor…
#> 5 ATL Hartsfield Jackson At… 33.6 -84.4 1026 -5 A America/New_Yo…
#> 6 AUS Austin Bergstrom Intl 30.2 -97.7 542 -6 A America/Chicago
#> # ℹ 95 more rows反连接则相反:它们返回 x 中所有在 y 中没有匹配的行。它们对于查找数据中隐式的缺失值很有用,这是 Section 18.3 的主题。隐式缺失值不会显示为 NA,而是仅仅以缺席的形式存在。例如,我们可以通过查找没有匹配目的地机场的航班来找到 airports 中缺失的行:
或者我们可以找出哪些 tailnum 在 planes 中是缺失的:
19.3.4 练习
找出(全年)延误最严重的 48 个小时。与
weather数据进行交叉引用。你能看到任何模式吗?-
想象你已经用这段代码找到了排名前 10 的最受欢迎的目的地:
你如何找到所有飞往这些目的地的航班?
每个出发的航班都有对应那个小时的天气数据吗?
那些在
planes中没有匹配记录的尾号有什么共同点?(提示:一个变量解释了约 90% 的问题。)向
planes添加一列,列出飞过那架飞机的每个carrier。你可能期望飞机和航空公司之间存在一种隐式关系,因为每架飞机都由一家航空公司运营。使用你在前面章节中学到的工具来证实或否定这个假设。将始发地和目的地机场的纬度和经度添加到
flights中。是在连接之前还是之后重命名列更容易?-
按目的地计算平均延误,然后与
airports数据框连接,这样你就可以显示延误的空间分布。这里有一个绘制美国地图的简单方法:airports |> semi_join(flights, join_by(faa == dest)) |> ggplot(aes(x = lon, y = lat)) + borders("state") + geom_point() + coord_quickmap()你可能想用点的大小或颜色来显示每个机场的平均延误。
2013 年 6 月 13 日发生了什么?绘制一张延误地图,然后用谷歌与天气进行交叉引用。
19.4 连接如何工作?
既然你已经使用过几次连接了,是时候学习更多关于它们如何工作的知识了,重点是 x 中的每一行如何与 y 中的行匹配。我们将首先介绍一种连接的可视化表示法,使用下面定义的简单 tibble,并如 Figure 19.2 所示。在这些例子中,我们将使用一个名为 key 的单个键和一个单个值列(val_x 和 val_y),但这些思想都适用于多个键和多个值。
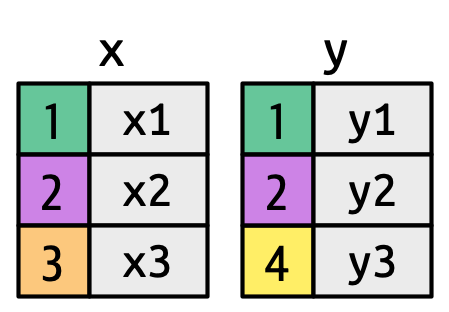
key 列将背景色映射到键值。灰色列代表被“携带”的值列。
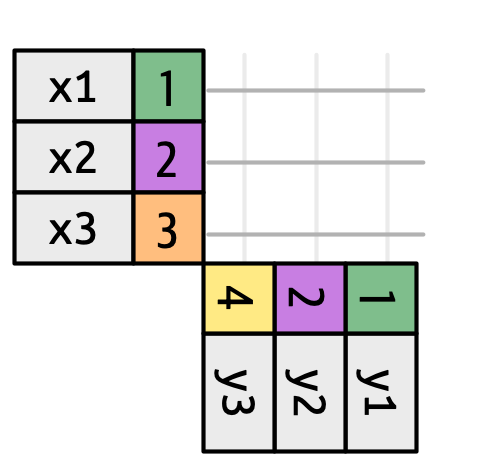
Figure 19.3 介绍了我们可视化表示法的基础。它将 x 和 y 之间的所有潜在匹配显示为从 x 的每一行和 y 的每一行画出的线的交点。输出中的行和列主要由 x 决定,所以 x 表是水平的,并与输出对齐。
为了描述一种特定类型的连接,我们用点来表示匹配。匹配决定了输出中的行,这是一个新的数据框,包含键、x 值和 y 值。例如,Figure 19.4 展示了一个内连接,当且仅当键相等时,行才被保留。
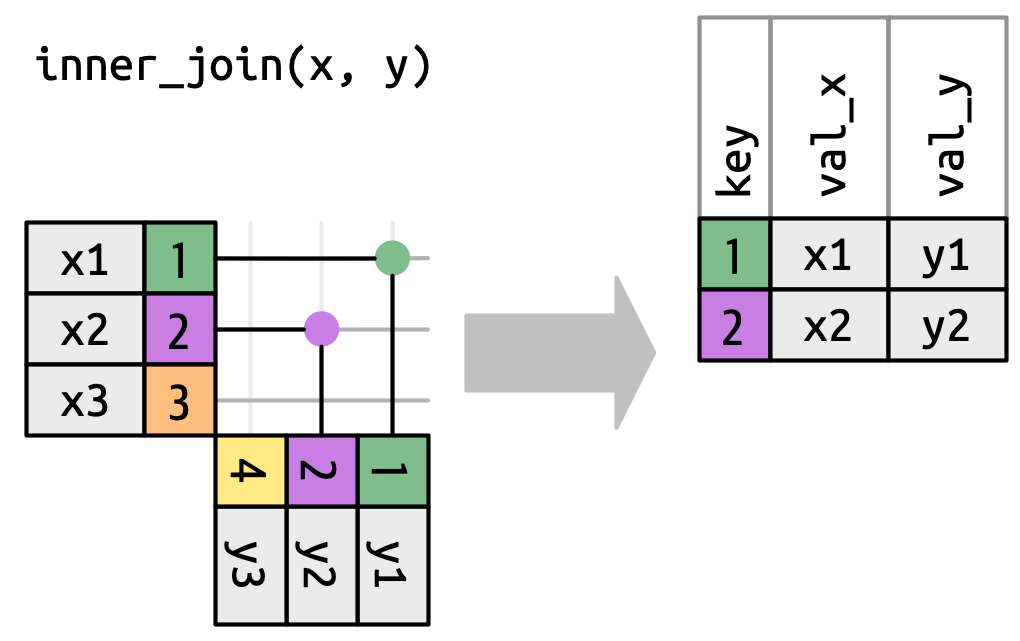
x 中的每一行与 y 中具有相同 key 值的行进行匹配。每个匹配都成为输出中的一行。
我们可以应用相同的原则来解释外连接 (outer joins),它保留出现在至少一个数据框中的观测值。这些连接通过向每个数据框添加一个额外的“虚拟”观测值来工作。这个观测值有一个在没有其他键匹配时能够匹配的键,并且值用 NA 填充。有三种类型的外连接:
-
左连接 (left join) 保留
x中的所有观测值,Figure 19.5。x的每一行都在输出中被保留,因为它可以回退到匹配y中的一行NA。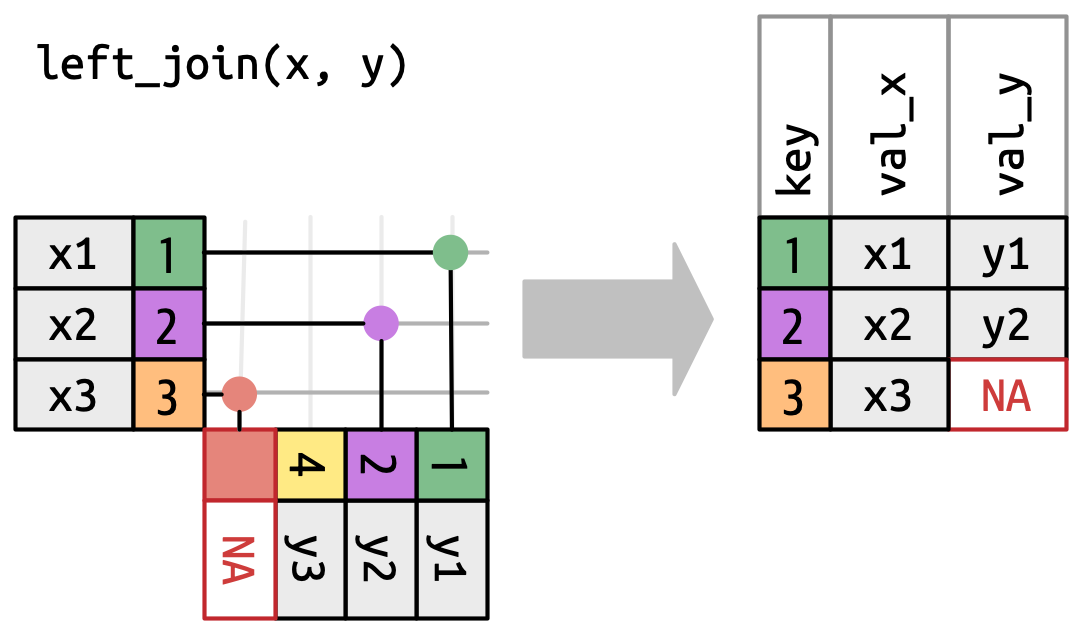
Figure 19.5: 左连接的可视化表示,其中 x中的每一行都出现在输出中。 -
右连接 (right join) 保留
y中的所有观测值,Figure 19.6。y的每一行都在输出中被保留,因为它可以回退到匹配x中的一行NA。输出仍然尽可能地与x匹配;来自y的任何多余的行都被添加到末尾。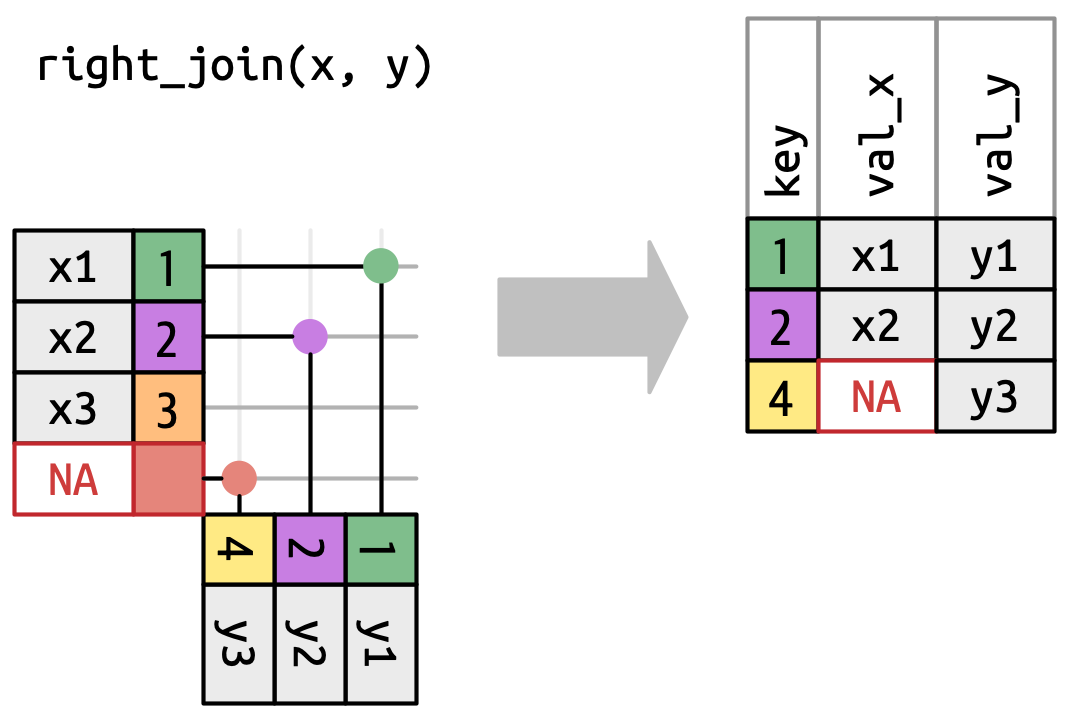
Figure 19.6: 右连接的可视化表示,其中 y的每一行都出现在输出中。 -
全连接 (full join) 保留出现在
x或y中的所有观测值,Figure 19.7。x和y的每一行都包含在输出中,因为x和y都有一个回退的NA行。同样,输出以x的所有行开始,然后是剩余的未匹配的y行。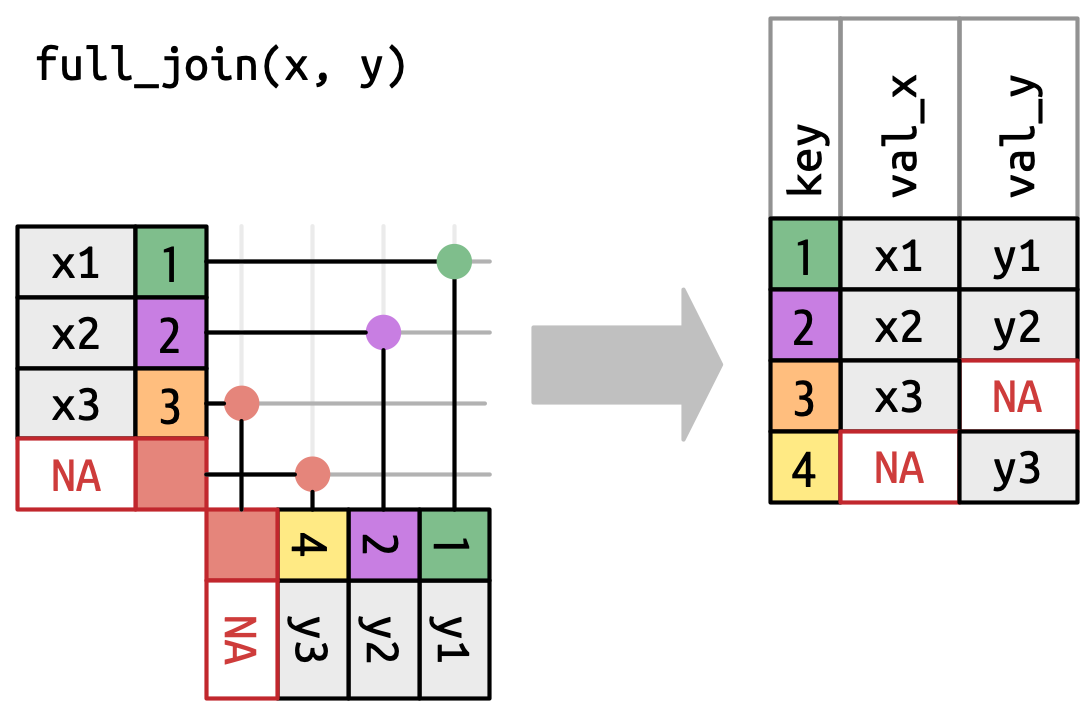
Figure 19.7: 全连接的可视化表示,其中 x和y中的每一行都出现在输出中。
另一种显示外连接类型差异的方法是使用维恩图,如 Figure 19.8 所示。然而,这不是一个很好的表示方法,因为尽管它可能会让你记起哪些行被保留了,但它未能说明列发生了什么。
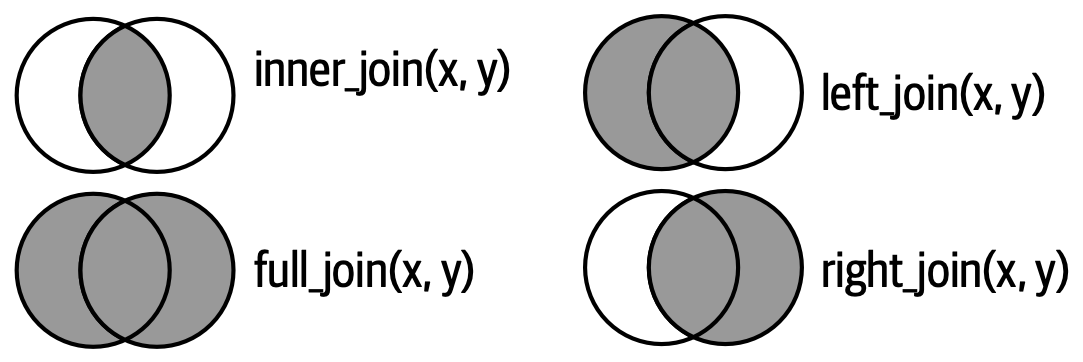
这里显示的连接是所谓的等值 (equi) 连接,其中如果键相等则行匹配。等值连接是最常见的连接类型,所以我们通常会省略等值前缀,只说“内连接”而不是“等值内连接”。我们将在 Section 19.5 中回到非等值连接。
19.4.1 行匹配
到目前为止,我们已经探讨了如果 x 中的一行与 y 中的零行或一行匹配会发生什么。如果它匹配多于一行会发生什么?要理解发生了什么,让我们首先将焦点缩小到 inner_join(),然后画一幅图,Figure 19.9。
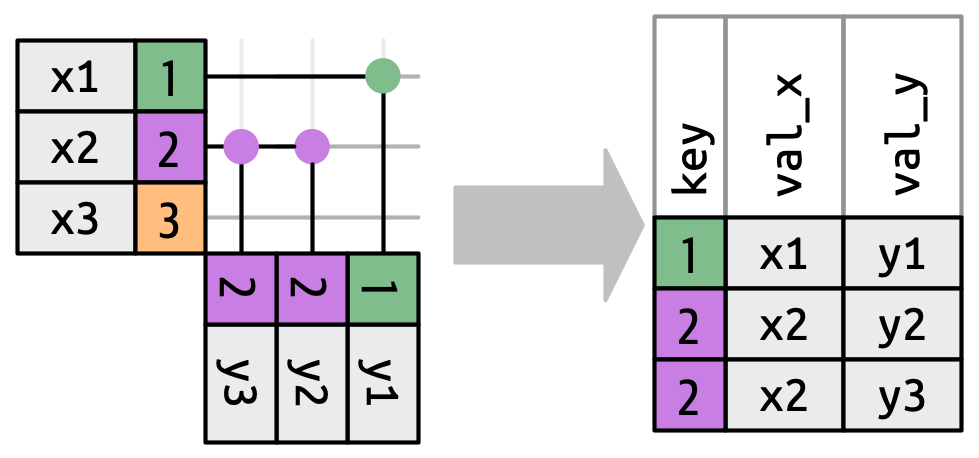
x 中的一行可以有三种匹配方式。x1 匹配 y 中的一行,x2 匹配 y 中的两行,x3 匹配 y 中的零行。注意,虽然 x 中有三行,输出中也有三行,但这些行之间没有直接的对应关系。
x 中的一行有三种可能的结果:
- 如果它不匹配任何东西,它就会被丢弃。
- 如果它匹配
y中的 1 行,它就会被保留。 - 如果它匹配
y中的多于 1 行,它会为每个匹配复制一次。
原则上,这意味着输出中的行与 x 中的行之间没有保证的对应关系,但在实践中,这很少引起问题。然而,有一个特别危险的情况可能会导致行的组合爆炸。想象一下连接以下两个表:
虽然 df1 中的第一行只匹配 df2 中的一行,但第二行和第三行都匹配两行。这有时被称为多对多 (many-to-many)连接,并且会导致 dplyr 发出警告:
df1 |>
inner_join(df2, join_by(key))
#> Warning in inner_join(df1, df2, join_by(key)): Detected an unexpected many-to-many relationship between `x` and `y`.
#> ℹ Row 2 of `x` matches multiple rows in `y`.
#> ℹ Row 2 of `y` matches multiple rows in `x`.
#> ℹ If a many-to-many relationship is expected, set `relationship =
#> "many-to-many"` to silence this warning.
#> # A tibble: 5 × 3
#> key val_x val_y
#> <dbl> <chr> <chr>
#> 1 1 x1 y1
#> 2 2 x2 y2
#> 3 2 x2 y3
#> 4 2 x3 y2
#> 5 2 x3 y3如果你是故意这样做的,你可以设置 relationship = "many-to-many",正如警告所建议的那样。
19.4.2 过滤连接
匹配的数量也决定了过滤连接的行为。半连接保留 x 中在 y 中有一个或多个匹配的行,如 Figure 19.10 所示。反连接保留 x 中匹配 y 中零行的行,如 Figure 19.11 所示。在这两种情况下,只有匹配的存在是重要的;它匹配多少次并不重要。这意味着过滤连接从不像变连接那样复制行。
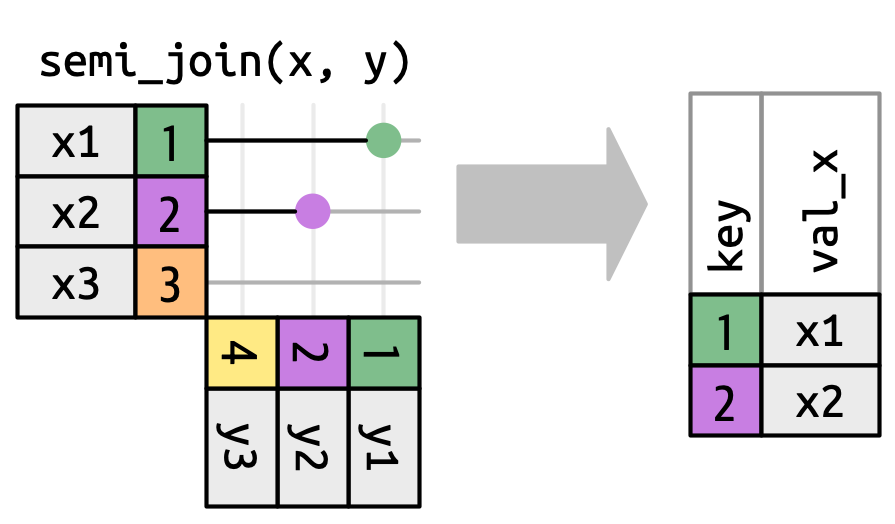
y 中的值不会影响输出。
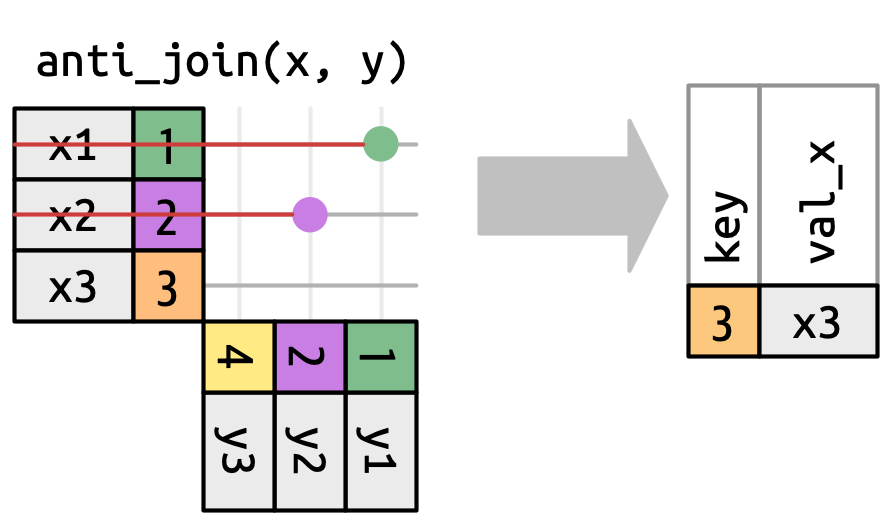
x 中删除在 y 中有匹配的行。
19.5 非等值连接
到目前为止,你只看到了等值连接,即如果 x 键等于 y 键,行就匹配。现在我们将放宽这个限制,讨论确定一对行是否匹配的其他方法。
但在此之前,我们需要重新审视我们上面做的一个简化。在等值连接中,x 键和 y 键总是相等的,所以我们只需要在输出中显示一个。我们可以通过 keep = TRUE 来请求 dplyr 保留两个键,这导致了下面的代码和 Figure 19.12 中重新绘制的 inner_join()。
x |> inner_join(y, join_by(key == key), keep = TRUE)
#> # A tibble: 2 × 4
#> key.x val_x key.y val_y
#> <dbl> <chr> <dbl> <chr>
#> 1 1 x1 1 y1
#> 2 2 x2 2 y2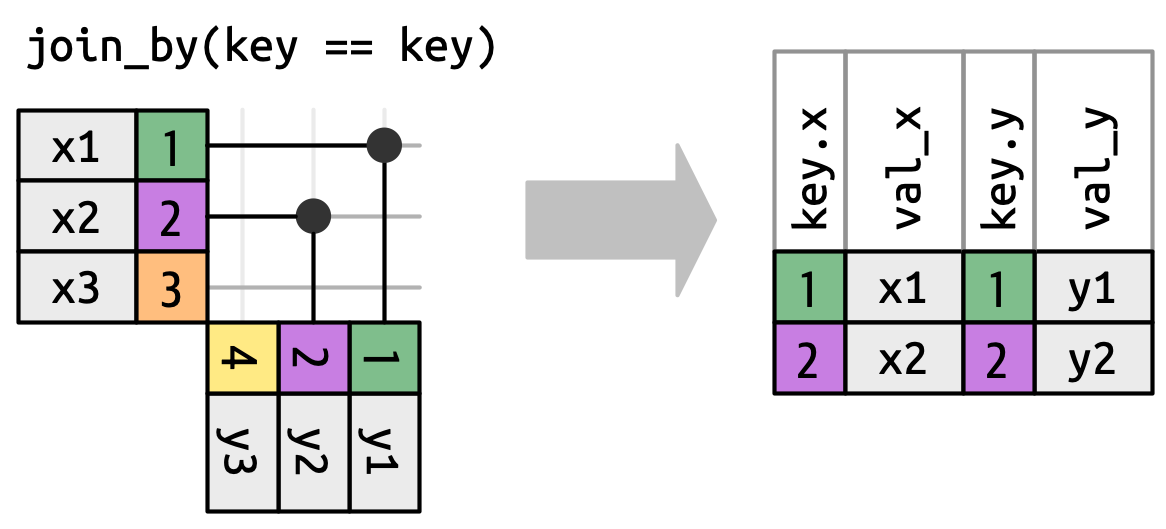
x 和 y 的键。
当我们从等值连接转向其他类型时,我们将总是显示键,因为键值通常会不同。例如,我们可以不再仅仅在 x$key 和 y$key 相等时匹配,而是在 x$key 大于或等于 y$key 时匹配,这导致了 Figure 19.13。dplyr 的连接函数理解等值连接和非等值连接之间的这种区别,所以当你执行非等值连接时,它总是会显示两个键。
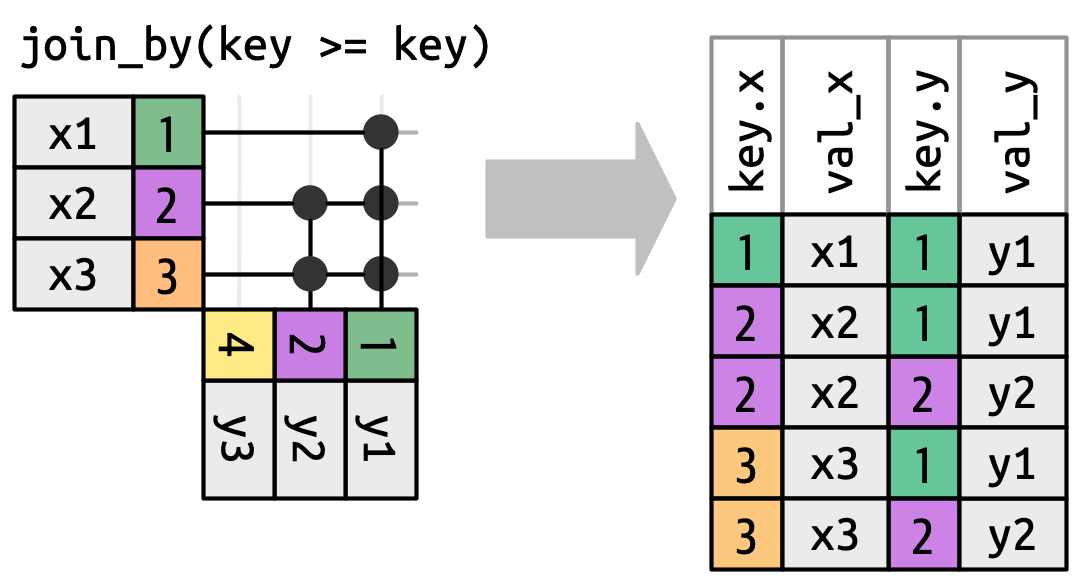
x 键必须大于或等于 y 键。许多行会产生多个匹配。
非等值连接不是一个特别有用的术语,因为它只告诉你连接不是什么,而不是它是什么。dplyr 通过识别四种特别有用的非等值连接类型来提供帮助:
- 交叉连接 (Cross joins) 匹配每一对行。
-
不等连接 (Inequality joins) 使用
<、<=、>和>=而不是==。 - 滚动连接 (Rolling joins) 类似于不等连接,但只找到最接近的匹配。
- 重叠连接 (Overlap joins) 是一种特殊类型的不等连接,旨在处理范围。
以下各节将更详细地描述这些类型中的每一种。
19.5.1 交叉连接
交叉连接匹配所有内容,如 Figure 19.14 所示,生成行的笛卡尔积。这意味着输出将有 nrow(x) * nrow(y) 行。
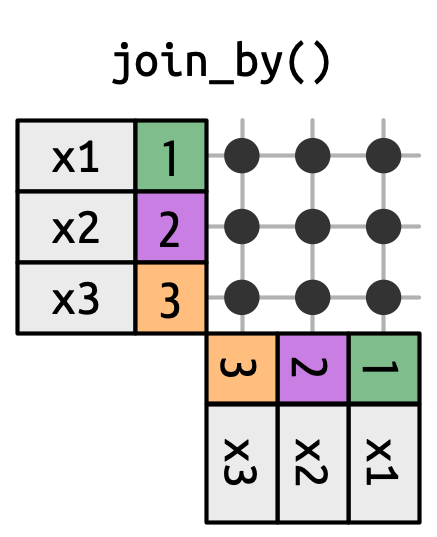
x 中的每一行与 y 中的每一行进行匹配。
交叉连接在生成排列时很有用。例如,下面的代码生成了所有可能的名字对。由于我们将 df 与自身连接,这有时被称为自连接 (self-join)。交叉连接使用一个不同的连接函数,因为当你匹配每一行时,内/左/右/全连接之间没有区别。
df <- tibble(name = c("John", "Simon", "Tracy", "Max"))
df |> cross_join(df)
#> # A tibble: 16 × 2
#> name.x name.y
#> <chr> <chr>
#> 1 John John
#> 2 John Simon
#> 3 John Tracy
#> 4 John Max
#> 5 Simon John
#> 6 Simon Simon
#> # ℹ 10 more rows19.5.2 不等连接
不等连接使用 <、<=、>= 或 > 来限制可能的匹配集,如 Figure 19.13 和 Figure 19.15 所示。
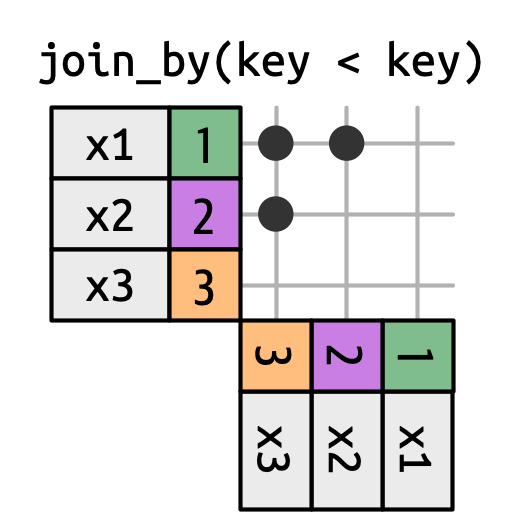
x 与 y 在 x 的键小于 y 的键的行上连接。这在左上角形成了一个三角形。
不等连接非常通用,以至于很难想出有意义的具体用例。一个有用的小技巧是使用它们来限制交叉连接,这样我们就可以生成所有组合而不是所有排列:
df <- tibble(id = 1:4, name = c("John", "Simon", "Tracy", "Max"))
df |> inner_join(df, join_by(id < id))
#> # A tibble: 6 × 4
#> id.x name.x id.y name.y
#> <int> <chr> <int> <chr>
#> 1 1 John 2 Simon
#> 2 1 John 3 Tracy
#> 3 1 John 4 Max
#> 4 2 Simon 3 Tracy
#> 5 2 Simon 4 Max
#> 6 3 Tracy 4 Max19.5.3 滚动连接
滚动连接是一种特殊类型的不等连接,在这种连接中,你得到的不是满足不等式的每一行,而只是最接近的那一行,如 Figure 19.16 所示。你可以通过添加 closest() 将任何不等连接变成滚动连接。例如,join_by(closest(x <= y)) 匹配大于或等于 x 的最小的 y,而 join_by(closest(x > y)) 匹配小于 x 的最大的 y。
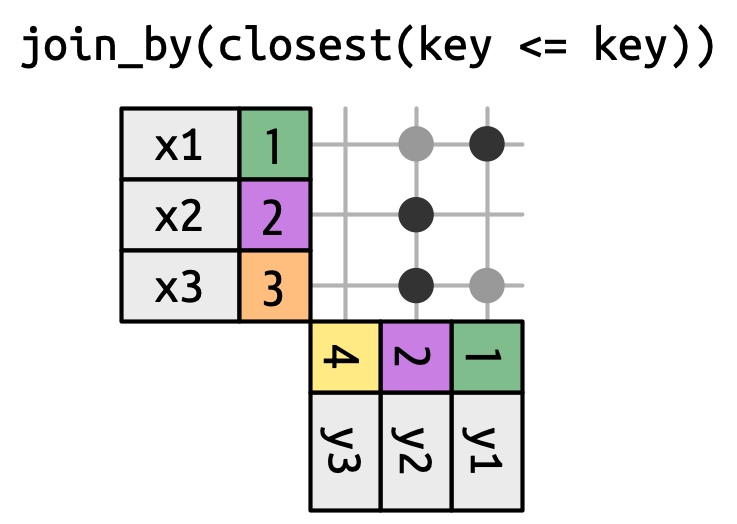
当你有两个日期表不能完美对齐,并且你想找到(例如)表 1 中在表 2 中某个日期之前(或之后)的最接近的日期时,滚动连接特别有用。
例如,假设你负责你办公室的派对策划委员会。你的公司相当吝啬,所以你们不是举办单独的派对,而是每个季度只举办一次派对。确定派对何时举行的规则有点复杂:派对总是在星期一,你跳过一月的第一周,因为很多人都在度假,而 2022 年第三季度的第一个星期一是 7 月 4 日,所以那必须推迟一周。这导致了以下的派对日期:
现在假设你有一张员工生日表:
set.seed(123)
employees <- tibble(
name = sample(babynames::babynames$name, 100),
birthday = ymd("2022-01-01") + (sample(365, 100, replace = TRUE) - 1)
)
employees
#> # A tibble: 100 × 2
#> name birthday
#> <chr> <date>
#> 1 Kemba 2022-01-22
#> 2 Orean 2022-06-26
#> 3 Kirstyn 2022-02-11
#> 4 Amparo 2022-11-11
#> 5 Belen 2022-03-25
#> 6 Rayshaun 2022-01-11
#> # ℹ 94 more rows对于每个员工,我们想找到在他们生日前(或生日当天)的最后一个派对日期。我们可以用一个滚动连接来表示这一点:
employees |>
left_join(parties, join_by(closest(birthday >= party)))
#> # A tibble: 100 × 4
#> name birthday q party
#> <chr> <date> <int> <date>
#> 1 Kemba 2022-01-22 1 2022-01-10
#> 2 Orean 2022-06-26 2 2022-04-04
#> 3 Kirstyn 2022-02-11 1 2022-01-10
#> 4 Amparo 2022-11-11 4 2022-10-03
#> 5 Belen 2022-03-25 1 2022-01-10
#> 6 Rayshaun 2022-01-11 1 2022-01-10
#> # ℹ 94 more rows然而,这种方法有一个问题:生日在 1 月 10 日之前的员工没有派对:
为了解决这个问题,我们需要用一种不同的方式来处理问题,即使用重叠连接。
19.5.4 重叠连接
重叠连接提供了三个使用不等连接来简化处理区间的辅助函数:
-
between(x, y_lower, y_upper)是x >= y_lower, x <= y_upper的简写。 -
within(x_lower, x_upper, y_lower, y_upper)是x_lower >= y_lower, x_upper <= y_upper的简写。 -
overlaps(x_lower, x_upper, y_lower, y_upper)是x_lower <= y_upper, x_upper >= y_lower的简写。
让我们继续生日的例子,看看你可能会如何使用它们。我们上面使用的策略有一个问题:在 1 月 1-9 日的生日前没有派对。所以,明确每个派对跨越的日期范围,并为那些早生的生日做一个特殊情况处理可能会更好:
parties <- tibble(
q = 1:4,
party = ymd(c("2022-01-10", "2022-04-04", "2022-07-11", "2022-10-03")),
start = ymd(c("2022-01-01", "2022-04-04", "2022-07-11", "2022-10-03")),
end = ymd(c("2022-04-03", "2022-07-11", "2022-10-02", "2022-12-31"))
)
parties
#> # A tibble: 4 × 4
#> q party start end
#> <int> <date> <date> <date>
#> 1 1 2022-01-10 2022-01-01 2022-04-03
#> 2 2 2022-04-04 2022-04-04 2022-07-11
#> 3 3 2022-07-11 2022-07-11 2022-10-02
#> 4 4 2022-10-03 2022-10-03 2022-12-31Hadley 在数据录入方面非常糟糕,所以他还想检查派对期间是否有重叠。一种方法是使用自连接来检查是否有任何开始-结束区间与另一个重叠:
parties |>
inner_join(parties, join_by(overlaps(start, end, start, end), q < q)) |>
select(start.x, end.x, start.y, end.y)
#> # A tibble: 1 × 4
#> start.x end.x start.y end.y
#> <date> <date> <date> <date>
#> 1 2022-04-04 2022-07-11 2022-07-11 2022-10-02哎呀,有重叠,所以让我们解决这个问题然后继续:
现在我们可以将每个员工与他们的派对匹配起来了。这是一个使用 unmatched = "error" 的好地方,因为我们想快速发现是否有任何员工没有被分配到派对。
employees |>
inner_join(parties, join_by(between(birthday, start, end)), unmatched = "error")
#> # A tibble: 100 × 6
#> name birthday q party start end
#> <chr> <date> <int> <date> <date> <date>
#> 1 Kemba 2022-01-22 1 2022-01-10 2022-01-01 2022-04-03
#> 2 Orean 2022-06-26 2 2022-04-04 2022-04-04 2022-07-10
#> 3 Kirstyn 2022-02-11 1 2022-01-10 2022-01-01 2022-04-03
#> 4 Amparo 2022-11-11 4 2022-10-03 2022-10-03 2022-12-31
#> 5 Belen 2022-03-25 1 2022-01-10 2022-01-01 2022-04-03
#> 6 Rayshaun 2022-01-11 1 2022-01-10 2022-01-01 2022-04-03
#> # ℹ 94 more rows19.5.5 练习
-
你能解释一下在这个等值连接中键发生了什么吗?为什么它们不同?
x |> full_join(y, join_by(key == key)) #> # A tibble: 4 × 3 #> key val_x val_y #> <dbl> <chr> <chr> #> 1 1 x1 y1 #> 2 2 x2 y2 #> 3 3 x3 <NA> #> 4 4 <NA> y3 x |> full_join(y, join_by(key == key), keep = TRUE) #> # A tibble: 4 × 4 #> key.x val_x key.y val_y #> <dbl> <chr> <dbl> <chr> #> 1 1 x1 1 y1 #> 2 2 x2 2 y2 #> 3 3 x3 NA <NA> #> 4 NA <NA> 4 y3 在查找是否有任何派对期间与另一个派对期间重叠时,我们在
join_by()中使用了q < q?为什么?如果移除这个不等式会发生什么?
19.6 总结
在本章中,你学习了如何使用变连接和过滤连接来组合来自一对数据框的数据。在此过程中,你学习了如何识别键,以及主键和外键之间的区别。你也理解了连接如何工作以及如何计算输出将有多少行。最后,你对非等值连接的力量有了初步的了解,并看到了一些有趣的用例。
本章结束了本书的“转换”部分,该部分的重点是你可以用于单个列和 tibble 的工具。你学习了用于处理逻辑向量、数字和完整表格的 dplyr 和基础函数,用于处理字符串的 stringr 函数,用于处理日期时间的 lubridate 函数,以及用于处理因子的 forcats 函数。
在本书的下一部分,你将学习更多关于如何将各种类型的数据以整洁的形式导入 R 的知识。