23 层级数据
23.1 引言
在本章中,你将学习数据 矩形化 (rectangling) 的艺术:将本质上是层级结构或树状结构的数据,转换为由行和列组成的矩形数据框。这一点非常重要,因为层级数据非常普遍,尤其是在处理来自网络的数据时。
要学习数据矩形化,你首先需要了解列表 (list),这种数据结构使得层级数据成为可能。然后,你将学习两个关键的 tidyr 函数:tidyr::unnest_longer() 和 tidyr::unnest_wider()。接着,我们将通过几个案例研究,反复应用这些简单的函数来解决实际问题。最后,我们将讨论 JSON,它是层级数据集最常见的来源,也是网络上一种常用的数据交换格式。
23.1.1 先决条件
在本章中,我们将使用 tidyr 包中的许多函数,它是 tidyverse 的核心成员。我们还将使用 repurrrsive 包来提供一些有趣的数据集用于矩形化练习,最后我们将使用 jsonlite 包将 JSON 文件读入 R 列表。
23.2 列表
到目前为止,你所处理的数据框都包含简单的向量,如整数、数字、字符、日期时间和因子。这些向量之所以简单,是因为它们是同质的 (homogeneous):每个元素都具有相同的数据类型。如果你想在同一个向量中存储不同类型的元素,你就需要一个 列表 (list),你可以用 list() 来创建它:
x1 <- list(1:4, "a", TRUE)
x1
#> [[1]]
#> [1] 1 2 3 4
#>
#> [[2]]
#> [1] "a"
#>
#> [[3]]
#> [1] TRUE为列表的组件 (component) 或 子元素 (children) 命名通常很方便,这和为 tibble 的列命名的方式相同:
x2 <- list(a = 1:2, b = 1:3, c = 1:4)
x2
#> $a
#> [1] 1 2
#>
#> $b
#> [1] 1 2 3
#>
#> $c
#> [1] 1 2 3 4即使对于这些非常简单的列表,打印出来也会占用相当大的空间。一个有用的替代方法是 str(),它会生成一个紧凑的 结构 (structure) 展示,淡化其内容:
如你所见,str() 将列表的每个子元素显示在单独的一行上。它会显示名称 (如果存在),然后是类型的缩写,最后是前几个值。
23.2.1 层级结构
列表可以包含任何类型的对象,包括其他列表。这使得它们非常适合表示层级 (树状) 结构:
随着列表变得越来越复杂,str() 的作用也越来越大,因为它能让你一目了然地看到层级结构:
当列表变得更大、更复杂时,str() 最终会开始失效,这时你就需要切换到 View()1。Figure 23.1 展示了调用 View(x5) 的结果。查看器开始只显示列表的顶层,但你可以交互地展开任何组件以查看更多内容,如 Figure 23.2 所示。RStudio 还会显示访问该元素所需写的代码,如 Figure 23.3 所示。我们将在 Section 27.3 回顾这段代码是如何工作的。
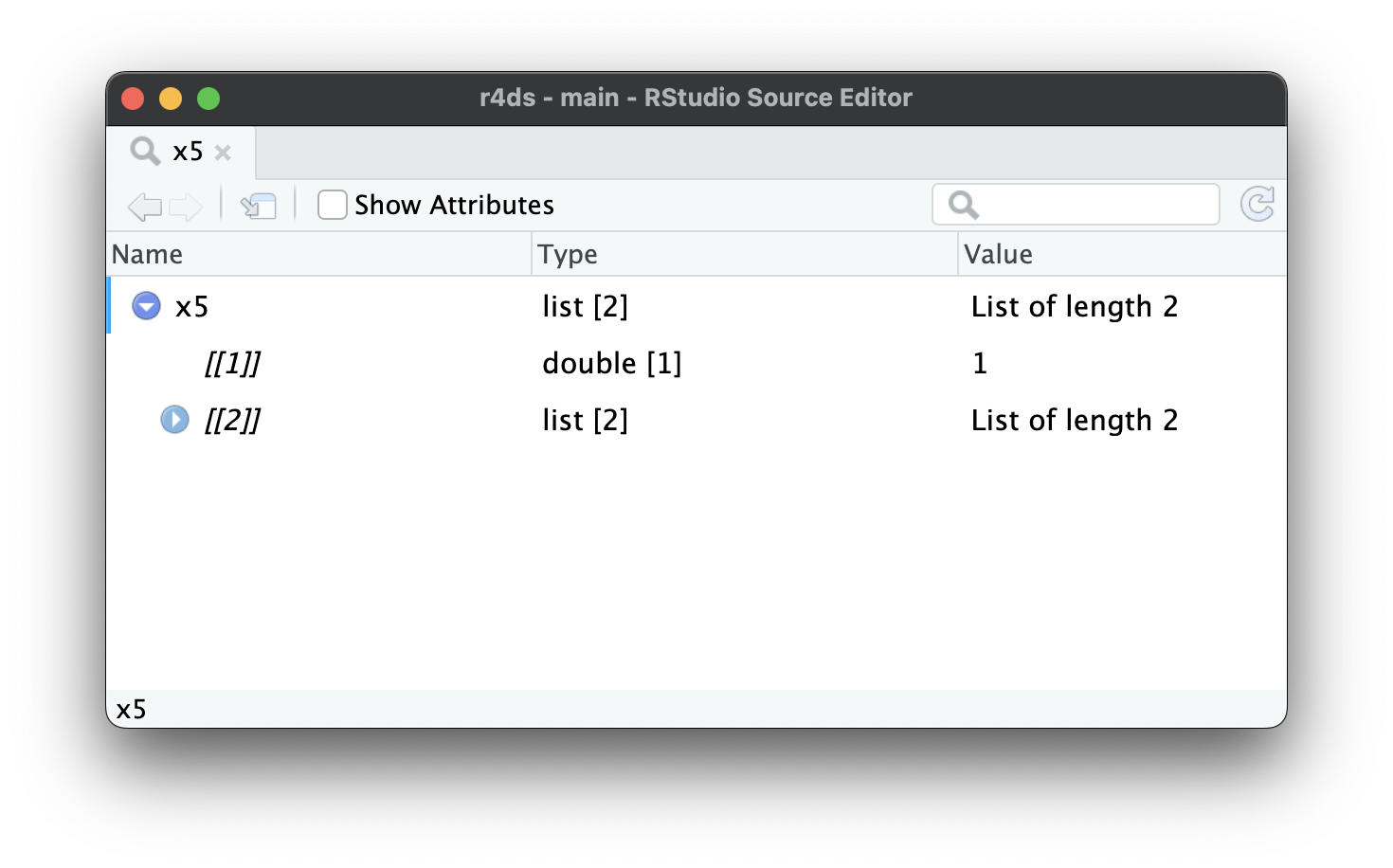
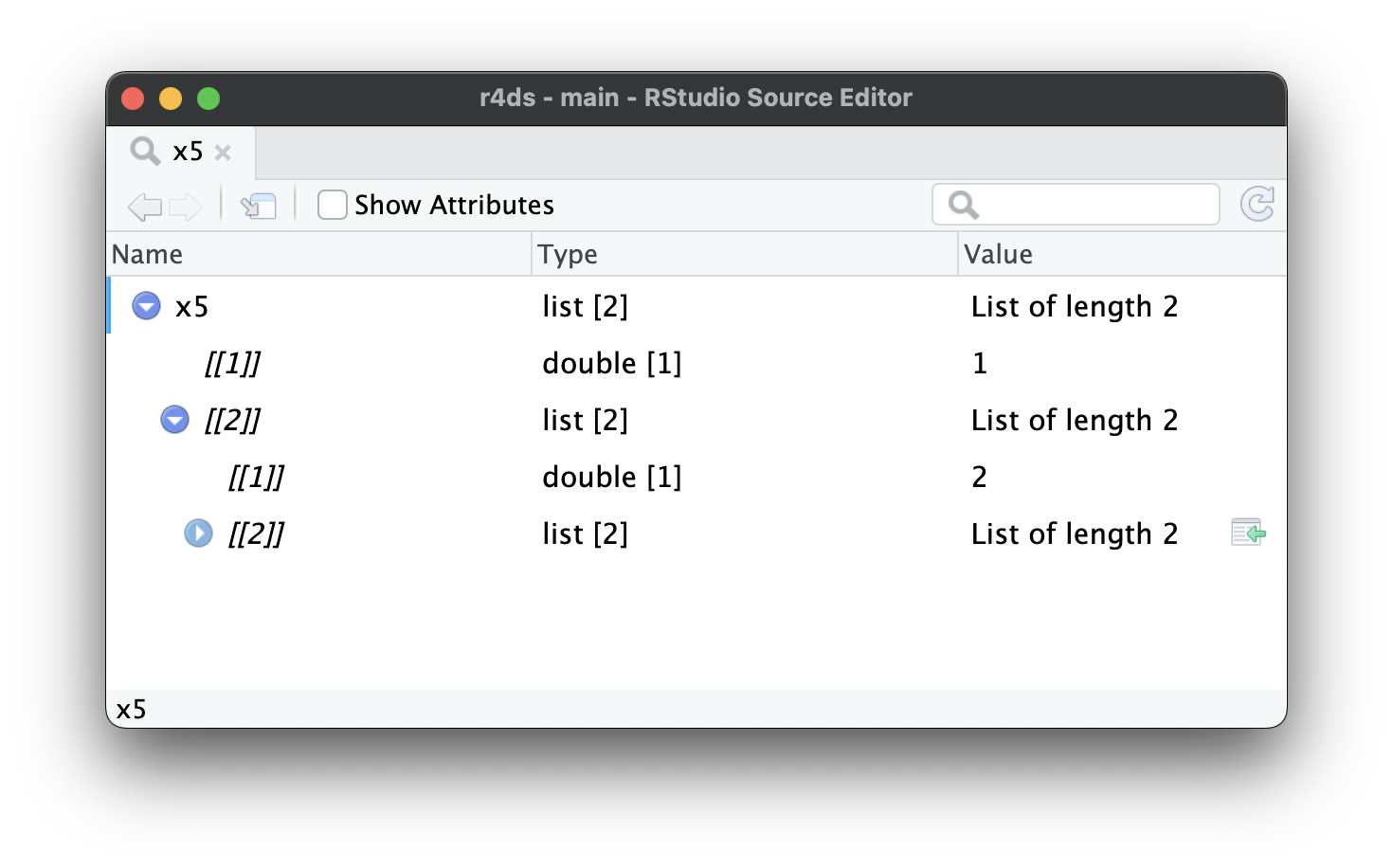
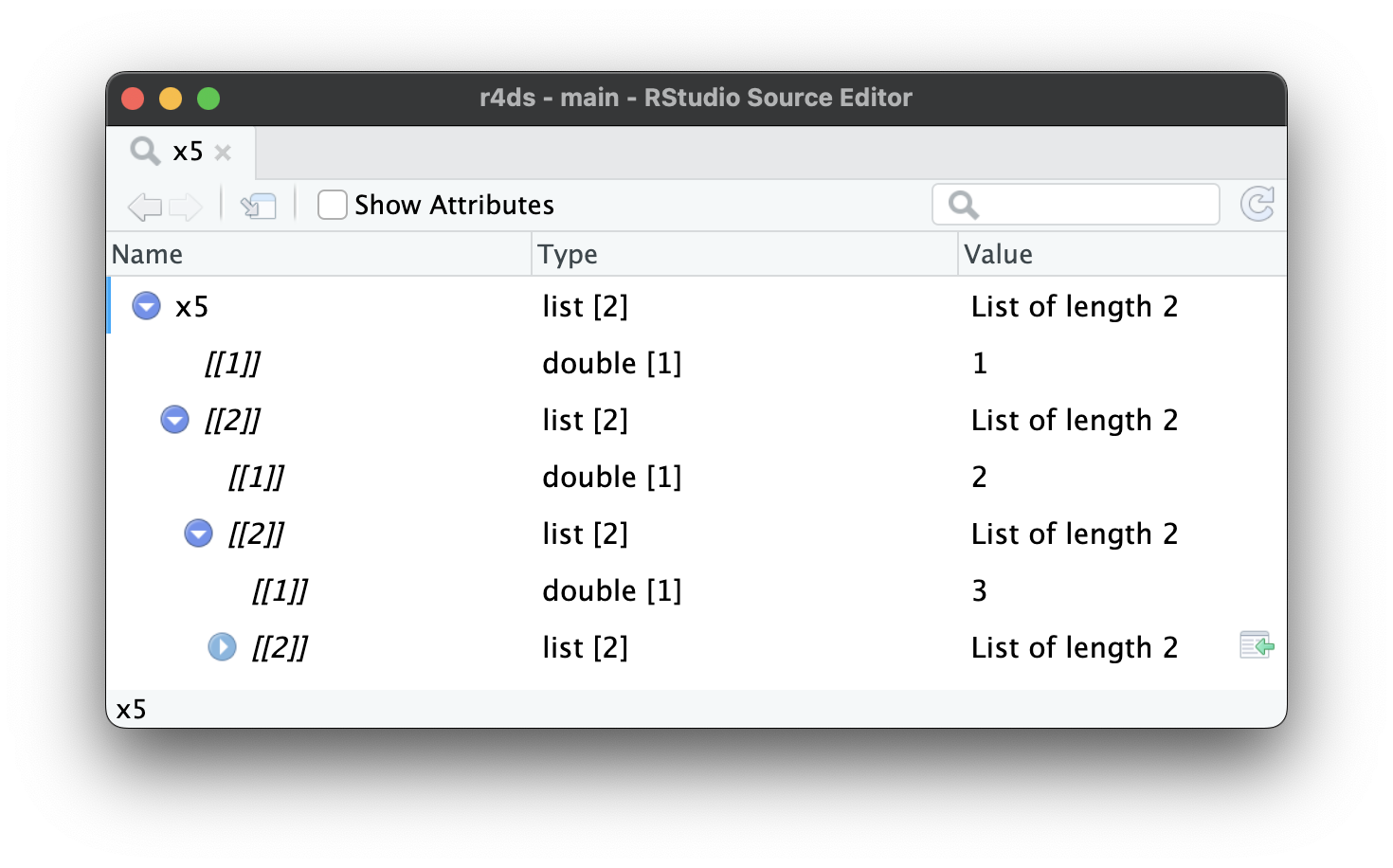
x5[[2]][[2]][[2]]。
23.2.2 列表列
列表也可以存在于 tibble 中,我们称之为列表列 (list-columns)。列表列很有用,因为它们允许你将通常不属于数据框的对象放入其中。特别地,列表列在 tidymodels 生态系统中使用很多,因为它们允许你将模型输出或重采样等内容存储在数据框中。
下面是列表列的一个简单示例:
tibble 中的列表没有什么特别之处;它们的行为就像任何其他列一样:
df |>
filter(x == 1)
#> # A tibble: 1 × 3
#> x y z
#> <int> <chr> <list>
#> 1 1 a <list [2]>使用列表列进行计算更加困难,但这是因为通常使用列表进行计算就更困难;我们将在 Chapter 26 中再讨论这个问题。在本章中,我们将专注于将列表列展开 (unnest) 为常规变量,以便你可以使用现有的工具来处理它们。
默认的打印方法只显示内容的粗略摘要。列表列可能任意复杂,所以没有很好的方法来打印它。如果你想查看它,你需要单独抽取出那个列表列,并应用你上面学到的技术之一,比如 df |> pull(z) |> str() 或 df |> pull(z) |> View()。
可以将列表放入 data.frame 的一列中,但这要麻烦得多,因为 data.frame() 将列表视为列的列表:
data.frame(x = list(1:3, 3:5))
#> x.1.3 x.3.5
#> 1 1 3
#> 2 2 4
#> 3 3 5你可以通过将其包装在 I() 中来强制 data.frame() 将列表视为行的列表,但结果打印得不是很好:
data.frame(
x = I(list(1:2, 3:5)),
y = c("1, 2", "3, 4, 5")
)
#> x y
#> 1 1, 2 1, 2
#> 2 3, 4, 5 3, 4, 5使用 tibble 的列表列更容易,因为 tibble() 将列表视为向量,并且其打印方法是为列表设计的。
23.3 展开
既然你已经学习了列表和列表列的基础知识,让我们来探讨如何将它们变回常规的行和列。这里我们将使用非常简单的示例数据,以便你了解基本思想;在下一节中,我们将切换到真实数据。
列表列倾向于以两种基本形式出现:命名的和未命名的。当子元素是 命名 的时,它们在每一行中往往具有相同的名称。例如,在 df1 中,列表列 y 的每个元素都有两个名为 a 和 b 的元素。命名的列表列很自然地展开为列:每个命名元素都成为一个新的命名列。
当子元素是 未命名 的时,元素的数量往往因行而异。例如,在 df2 中,列表列 y 的元素是未命名的,长度从一到三不等。未命名的列表列很自然地展开为行:每个子元素将得到一行。
tidyr 为这两种情况提供了两个函数:unnest_wider() 和 unnest_longer()。以下各节将解释它们如何工作。
23.3.1 unnest_wider()
当每一行都有相同数量且名称相同的元素时,比如 df1,很自然地可以用 unnest_wider() 将每个组件放入其自己的列中:
df1 |>
unnest_wider(y)
#> # A tibble: 3 × 3
#> x a b
#> <dbl> <dbl> <dbl>
#> 1 1 11 12
#> 2 2 21 22
#> 3 3 31 32默认情况下,新列的名称完全来自列表元素的名称,但你可以使用 names_sep 参数来要求它们将列名和元素名组合起来。这对于消除重复的名称很有用。
df1 |>
unnest_wider(y, names_sep = "_")
#> # A tibble: 3 × 3
#> x y_a y_b
#> <dbl> <dbl> <dbl>
#> 1 1 11 12
#> 2 2 21 22
#> 3 3 31 32
23.3.2 unnest_longer()
当每一行都包含一个未命名的列表时,最自然的方式是用 unnest_longer() 将每个元素放入其自己的行中:
df2 |>
unnest_longer(y)
#> # A tibble: 6 × 2
#> x y
#> <dbl> <dbl>
#> 1 1 11
#> 2 1 12
#> 3 1 13
#> 4 2 21
#> 5 3 31
#> 6 3 32请注意 x 是如何为 y 中的每个元素复制的:对于列表列中的每个元素,我们都会得到一行输出。但是,如果其中一个元素是空的,如下面的例子所示,会发生什么呢?
df6 <- tribble(
~x, ~y,
"a", list(1, 2),
"b", list(3),
"c", list()
)
df6 |> unnest_longer(y)
#> # A tibble: 3 × 2
#> x y
#> <chr> <dbl>
#> 1 a 1
#> 2 a 2
#> 3 b 3我们在输出中得到零行,所以该行实际上消失了。如果你想保留那一行,并在 y 中添加 NA,请设置 keep_empty = TRUE。
23.3.3 类型不一致
如果你展开一个包含不同类型向量的列表列,会发生什么?例如,看下面的数据集,其中列表列 y 包含两个数字、一个字符和一个逻辑值,这些通常不能混合在单个列中。
unnest_longer() 总是保持列集合不变,同时改变行的数量。那么会发生什么呢?unnest_longer() 如何在保持 y 中所有内容的同时产生五行?
df4 |>
unnest_longer(y)
#> # A tibble: 4 × 2
#> x y
#> <chr> <list>
#> 1 a <dbl [1]>
#> 2 b <chr [1]>
#> 3 b <lgl [1]>
#> 4 b <dbl [1]>如你所见,输出包含一个列表列,但该列表列的每个元素都包含一个单一元素。因为 unnest_longer() 找不到一个通用的向量类型,它将原始类型保留在一个列表列中。你可能会想,这是否违反了列的每个元素必须是相同类型的规定。并没有:每个元素都是一个列表,尽管其内容是不同类型的。
处理不一致的类型具有挑战性,具体细节取决于问题的确切性质和你的目标,但你很可能需要来自 Chapter 26 的工具。
23.3.4 其他函数
tidyr 还有一些其他有用的矩形化函数,我们在这本书中不会涉及:
-
unnest_auto()会根据列表列的结构自动在unnest_longer()和unnest_wider()之间进行选择。它对于快速探索非常棒,但最终这不是一个好主意,因为它没有强迫你理解你的数据是如何组织的,并使你的代码更难理解。 -
unnest()会同时扩展行和列。当你有一个包含二维结构(如数据框)的列表列时,它很有用,这在这本书中你看不到,但如果你使用 tidymodels 生态系统,你可能会遇到。
了解这些函数是很好的,因为你在阅读他人的代码或自己处理更罕见的矩形化挑战时可能会遇到它们。
23.3.5 练习
当你对像
df2这样的未命名列表列使用unnest_wider()时会发生什么?现在需要哪个参数?缺失值会发生什么变化?当你对像
df1这样的命名列表列使用unnest_longer()时会发生什么?你在输出中得到了哪些额外的信息?你如何抑制这些额外的细节?-
你有时会遇到具有多个值对齐的列表列的数据框。例如,在下面的数据框中,
y和z的值是对齐的(即在一行内y和z的长度总是相同的,并且y的第一个值对应于z的第一个值)。如果你对这个数据框应用两次unnest_longer()调用会发生什么?你如何保留x和y之间的关系?(提示:仔细阅读文档)。
23.4 案例研究
我们上面使用的简单示例与真实数据之间的主要区别在于,真实数据通常包含多层嵌套,需要多次调用 unnest_longer() 和/或 unnest_wider()。为了展示这一点,本节将使用 repurrrsive 包中的数据集来解决三个真实的矩形化挑战。
23.4.1 非常宽的数据
我们从 gh_repos 开始。这是一个列表,包含了从 GitHub API 检索到的一系列 GitHub 仓库的数据。这是一个非常深层嵌套的列表,因此很难在本书中展示其结构;我们建议在继续之前,先用 View(gh_repos) 自己探索一下。
gh_repos 是一个列表,但我们的工具是针对列表列的,所以我们首先将它放入一个 tibble 中。由于我们稍后会讲到的原因,我们称此列为 json。
repos <- tibble(json = gh_repos)
repos
#> # A tibble: 6 × 1
#> json
#> <list>
#> 1 <list [30]>
#> 2 <list [30]>
#> 3 <list [30]>
#> 4 <list [26]>
#> 5 <list [30]>
#> 6 <list [30]>这个 tibble 包含 6 行,每行对应 gh_repos 的一个子元素。每一行都包含一个未命名的列表,有 26 或 30 行。由于这些是未命名的,我们将从 unnest_longer() 开始,将每个子元素放入其自己的行中:
repos |>
unnest_longer(json)
#> # A tibble: 176 × 1
#> json
#> <list>
#> 1 <named list [68]>
#> 2 <named list [68]>
#> 3 <named list [68]>
#> 4 <named list [68]>
#> 5 <named list [68]>
#> 6 <named list [68]>
#> # ℹ 170 more rows乍一看,似乎我们并没有改善情况:虽然我们有了更多的行(176 而不是 6),但 json 的每个元素仍然是一个列表。然而,有一个重要的区别:现在每个元素都是一个 命名 列表,所以我们可以使用 unnest_wider() 将每个元素放入其自己的列中:
repos |>
unnest_longer(json) |>
unnest_wider(json)
#> # A tibble: 176 × 68
#> id name full_name owner private html_url
#> <int> <chr> <chr> <list> <lgl> <chr>
#> 1 61160198 after gaborcsardi/after <named list> FALSE https://github…
#> 2 40500181 argufy gaborcsardi/argu… <named list> FALSE https://github…
#> 3 36442442 ask gaborcsardi/ask <named list> FALSE https://github…
#> 4 34924886 baseimports gaborcsardi/base… <named list> FALSE https://github…
#> 5 61620661 citest gaborcsardi/cite… <named list> FALSE https://github…
#> 6 33907457 clisymbols gaborcsardi/clis… <named list> FALSE https://github…
#> # ℹ 170 more rows
#> # ℹ 62 more variables: description <chr>, fork <lgl>, url <chr>, …这已经成功了,但结果有点让人不知所措:列太多了,以至于 tibble 甚至没有打印出所有的列!我们可以用 names() 看到所有的列;这里我们看一下前 10 个:
repos |>
unnest_longer(json) |>
unnest_wider(json) |>
names() |>
head(10)
#> [1] "id" "name" "full_name" "owner" "private"
#> [6] "html_url" "description" "fork" "url" "forks_url"让我们挑出一些看起来有趣的列:
repos |>
unnest_longer(json) |>
unnest_wider(json) |>
select(id, full_name, owner, description)
#> # A tibble: 176 × 4
#> id full_name owner description
#> <int> <chr> <list> <chr>
#> 1 61160198 gaborcsardi/after <named list [17]> Run Code in the Backgro…
#> 2 40500181 gaborcsardi/argufy <named list [17]> Declarative function ar…
#> 3 36442442 gaborcsardi/ask <named list [17]> Friendly CLI interactio…
#> 4 34924886 gaborcsardi/baseimports <named list [17]> Do we get warnings for …
#> 5 61620661 gaborcsardi/citest <named list [17]> Test R package and repo…
#> 6 33907457 gaborcsardi/clisymbols <named list [17]> Unicode symbols for CLI…
#> # ℹ 170 more rows你可以利用这个来回溯理解 gh_repos 的结构:每个子元素都是一个 GitHub 用户,包含一个他们创建的最多 30 个 GitHub 仓库的列表。
owner 是另一个列表列,由于它包含一个命名的列表,我们可以使用 unnest_wider() 来获取其值:
repos |>
unnest_longer(json) |>
unnest_wider(json) |>
select(id, full_name, owner, description) |>
unnest_wider(owner)
#> Error in `unnest_wider()`:
#> ! Can't duplicate names between the affected columns and the original
#> data.
#> ✖ These names are duplicated:
#> ℹ `id`, from `owner`.
#> ℹ Use `names_sep` to disambiguate using the column name.
#> ℹ Or use `names_repair` to specify a repair strategy.哦哦,这个列表列也包含一个 id 列,我们不能在同一个数据框中有两个 id 列。如建议的那样,让我们使用 names_sep 来解决这个问题:
repos |>
unnest_longer(json) |>
unnest_wider(json) |>
select(id, full_name, owner, description) |>
unnest_wider(owner, names_sep = "_")
#> # A tibble: 176 × 20
#> id full_name owner_login owner_id owner_avatar_url
#> <int> <chr> <chr> <int> <chr>
#> 1 61160198 gaborcsardi/after gaborcsardi 660288 https://avatars.gith…
#> 2 40500181 gaborcsardi/argufy gaborcsardi 660288 https://avatars.gith…
#> 3 36442442 gaborcsardi/ask gaborcsardi 660288 https://avatars.gith…
#> 4 34924886 gaborcsardi/baseimports gaborcsardi 660288 https://avatars.gith…
#> 5 61620661 gaborcsardi/citest gaborcsardi 660288 https://avatars.gith…
#> 6 33907457 gaborcsardi/clisymbols gaborcsardi 660288 https://avatars.gith…
#> # ℹ 170 more rows
#> # ℹ 15 more variables: owner_gravatar_id <chr>, owner_url <chr>, …这又得到了一个很宽的数据集,但你可以感觉到 owner 似乎包含了大量关于“拥有”该仓库的人的额外数据。
23.4.2 关系数据
嵌套数据有时用于表示我们通常会分散在多个数据框中的数据。例如,got_chars 包含了关于《权力的游戏》书籍和电视剧中出现的角色的数据。和 gh_repos 一样,它是一个列表,所以我们首先将它转换成一个 tibble 的列表列:
chars <- tibble(json = got_chars)
chars
#> # A tibble: 30 × 1
#> json
#> <list>
#> 1 <named list [18]>
#> 2 <named list [18]>
#> 3 <named list [18]>
#> 4 <named list [18]>
#> 5 <named list [18]>
#> 6 <named list [18]>
#> # ℹ 24 more rowsjson 列包含命名的元素,所以我们先用 unnest_wider() 将其展开:
chars |>
unnest_wider(json)
#> # A tibble: 30 × 18
#> url id name gender culture born
#> <chr> <int> <chr> <chr> <chr> <chr>
#> 1 https://www.anapio… 1022 Theon Greyjoy Male "Ironborn" "In 278 AC or …
#> 2 https://www.anapio… 1052 Tyrion Lannist… Male "" "In 273 AC, at…
#> 3 https://www.anapio… 1074 Victarion Grey… Male "Ironborn" "In 268 AC or …
#> 4 https://www.anapio… 1109 Will Male "" ""
#> 5 https://www.anapio… 1166 Areo Hotah Male "Norvoshi" "In 257 AC or …
#> 6 https://www.anapio… 1267 Chett Male "" "At Hag's Mire"
#> # ℹ 24 more rows
#> # ℹ 12 more variables: died <chr>, alive <lgl>, titles <list>, …然后选择几列以便于阅读:
characters <- chars |>
unnest_wider(json) |>
select(id, name, gender, culture, born, died, alive)
characters
#> # A tibble: 30 × 7
#> id name gender culture born died
#> <int> <chr> <chr> <chr> <chr> <chr>
#> 1 1022 Theon Greyjoy Male "Ironborn" "In 278 AC or 27… ""
#> 2 1052 Tyrion Lannister Male "" "In 273 AC, at C… ""
#> 3 1074 Victarion Greyjoy Male "Ironborn" "In 268 AC or be… ""
#> 4 1109 Will Male "" "" "In 297 AC, at…
#> 5 1166 Areo Hotah Male "Norvoshi" "In 257 AC or be… ""
#> 6 1267 Chett Male "" "At Hag's Mire" "In 299 AC, at…
#> # ℹ 24 more rows
#> # ℹ 1 more variable: alive <lgl>这个数据集也包含许多列表列:
chars |>
unnest_wider(json) |>
select(id, where(is.list))
#> # A tibble: 30 × 8
#> id titles aliases allegiances books povBooks tvSeries playedBy
#> <int> <list> <list> <list> <list> <list> <list> <list>
#> 1 1022 <chr [2]> <chr [4]> <chr [1]> <chr [3]> <chr> <chr> <chr>
#> 2 1052 <chr [2]> <chr [11]> <chr [1]> <chr [2]> <chr> <chr> <chr>
#> 3 1074 <chr [2]> <chr [1]> <chr [1]> <chr [3]> <chr> <chr> <chr>
#> 4 1109 <chr [1]> <chr [1]> <NULL> <chr [1]> <chr> <chr> <chr>
#> 5 1166 <chr [1]> <chr [1]> <chr [1]> <chr [3]> <chr> <chr> <chr>
#> 6 1267 <chr [1]> <chr [1]> <NULL> <chr [2]> <chr> <chr> <chr>
#> # ℹ 24 more rows让我们来探索 titles 列。它是一个未命名的列表列,所以我们把它展开成行:
chars |>
unnest_wider(json) |>
select(id, titles) |>
unnest_longer(titles)
#> # A tibble: 59 × 2
#> id titles
#> <int> <chr>
#> 1 1022 Prince of Winterfell
#> 2 1022 Lord of the Iron Islands (by law of the green lands)
#> 3 1052 Acting Hand of the King (former)
#> 4 1052 Master of Coin (former)
#> 5 1074 Lord Captain of the Iron Fleet
#> 6 1074 Master of the Iron Victory
#> # ℹ 53 more rows你可能期望看到这些数据在它自己的表中,因为这样很容易按需连接到角色数据。让我们这样做,这需要一点清理:删除包含空字符串的行,并将 titles 重命名为 title,因为现在每行只包含一个头衔。
titles <- chars |>
unnest_wider(json) |>
select(id, titles) |>
unnest_longer(titles) |>
filter(titles != "") |>
rename(title = titles)
titles
#> # A tibble: 52 × 2
#> id title
#> <int> <chr>
#> 1 1022 Prince of Winterfell
#> 2 1022 Lord of the Iron Islands (by law of the green lands)
#> 3 1052 Acting Hand of the King (former)
#> 4 1052 Master of Coin (former)
#> 5 1074 Lord Captain of the Iron Fleet
#> 6 1074 Master of the Iron Victory
#> # ℹ 46 more rows你可以想象为每个列表列创建这样的一个表,然后在需要时使用连接将它们与角色数据结合起来。
23.4.3 深度嵌套
我们将用一个非常深度嵌套的列表列来结束这些案例研究,它需要反复使用 unnest_wider() 和 unnest_longer() 来解开:gmaps_cities。这是一个两列的 tibble,包含五个城市名称和使用谷歌的 地理编码 API 来确定它们位置的结果:
gmaps_cities
#> # A tibble: 5 × 2
#> city json
#> <chr> <list>
#> 1 Houston <named list [2]>
#> 2 Washington <named list [2]>
#> 3 New York <named list [2]>
#> 4 Chicago <named list [2]>
#> 5 Arlington <named list [2]>json 是一个带有内部名称的列表列,所以我们从 unnest_wider() 开始:
gmaps_cities |>
unnest_wider(json)
#> # A tibble: 5 × 3
#> city results status
#> <chr> <list> <chr>
#> 1 Houston <list [1]> OK
#> 2 Washington <list [2]> OK
#> 3 New York <list [1]> OK
#> 4 Chicago <list [1]> OK
#> 5 Arlington <list [2]> OK这给了我们 status 和 results。我们将丢弃 status 列,因为它们都是 OK;在真实的分析中,你还需要捕获所有 status != "OK" 的行,并找出问题所在。results 是一个未命名的列表,有一或两个元素(我们很快会看到为什么),所以我们将它展开成行:
gmaps_cities |>
unnest_wider(json) |>
select(-status) |>
unnest_longer(results)
#> # A tibble: 7 × 2
#> city results
#> <chr> <list>
#> 1 Houston <named list [5]>
#> 2 Washington <named list [5]>
#> 3 Washington <named list [5]>
#> 4 New York <named list [5]>
#> 5 Chicago <named list [5]>
#> 6 Arlington <named list [5]>
#> # ℹ 1 more row现在 results 是一个命名的列表,所以我们使用 unnest_wider():
locations <- gmaps_cities |>
unnest_wider(json) |>
select(-status) |>
unnest_longer(results) |>
unnest_wider(results)
locations
#> # A tibble: 7 × 6
#> city address_components formatted_address geometry
#> <chr> <list> <chr> <list>
#> 1 Houston <list [4]> Houston, TX, USA <named list [4]>
#> 2 Washington <list [2]> Washington, USA <named list [4]>
#> 3 Washington <list [4]> Washington, DC, USA <named list [4]>
#> 4 New York <list [3]> New York, NY, USA <named list [4]>
#> 5 Chicago <list [4]> Chicago, IL, USA <named list [4]>
#> 6 Arlington <list [4]> Arlington, TX, USA <named list [4]>
#> # ℹ 1 more row
#> # ℹ 2 more variables: place_id <chr>, types <list>现在我们可以看到为什么有两个城市得到了两个结果:华盛顿 (Washington) 匹配了华盛顿州 (Washington state) 和华盛顿特区 (Washington, DC),阿灵顿 (Arlington) 匹配了弗吉尼亚州的阿灵顿 (Arlington, Virginia) 和德克萨斯州的阿灵顿 (Arlington, Texas)。
从这里我们可以走向几个不同的方向。我们可能想确定匹配的精确位置,这存储在 geometry 列表列中:
locations |>
select(city, formatted_address, geometry) |>
unnest_wider(geometry)
#> # A tibble: 7 × 6
#> city formatted_address bounds location location_type
#> <chr> <chr> <list> <list> <chr>
#> 1 Houston Houston, TX, USA <named list [2]> <named list> APPROXIMATE
#> 2 Washington Washington, USA <named list [2]> <named list> APPROXIMATE
#> 3 Washington Washington, DC, USA <named list [2]> <named list> APPROXIMATE
#> 4 New York New York, NY, USA <named list [2]> <named list> APPROXIMATE
#> 5 Chicago Chicago, IL, USA <named list [2]> <named list> APPROXIMATE
#> 6 Arlington Arlington, TX, USA <named list [2]> <named list> APPROXIMATE
#> # ℹ 1 more row
#> # ℹ 1 more variable: viewport <list>这给了我们新的 bounds(一个矩形区域)和 location(一个点)。我们可以展开 location 来查看纬度 (lat) 和经度 (lng):
locations |>
select(city, formatted_address, geometry) |>
unnest_wider(geometry) |>
unnest_wider(location)
#> # A tibble: 7 × 7
#> city formatted_address bounds lat lng location_type
#> <chr> <chr> <list> <dbl> <dbl> <chr>
#> 1 Houston Houston, TX, USA <named list [2]> 29.8 -95.4 APPROXIMATE
#> 2 Washington Washington, USA <named list [2]> 47.8 -121. APPROXIMATE
#> 3 Washington Washington, DC, USA <named list [2]> 38.9 -77.0 APPROXIMATE
#> 4 New York New York, NY, USA <named list [2]> 40.7 -74.0 APPROXIMATE
#> 5 Chicago Chicago, IL, USA <named list [2]> 41.9 -87.6 APPROXIMATE
#> 6 Arlington Arlington, TX, USA <named list [2]> 32.7 -97.1 APPROXIMATE
#> # ℹ 1 more row
#> # ℹ 1 more variable: viewport <list>提取边界需要更多几个步骤:
locations |>
select(city, formatted_address, geometry) |>
unnest_wider(geometry) |>
# 专注于感兴趣的变量
select(!location:viewport) |>
unnest_wider(bounds)
#> # A tibble: 7 × 4
#> city formatted_address northeast southwest
#> <chr> <chr> <list> <list>
#> 1 Houston Houston, TX, USA <named list [2]> <named list [2]>
#> 2 Washington Washington, USA <named list [2]> <named list [2]>
#> 3 Washington Washington, DC, USA <named list [2]> <named list [2]>
#> 4 New York New York, NY, USA <named list [2]> <named list [2]>
#> 5 Chicago Chicago, IL, USA <named list [2]> <named list [2]>
#> 6 Arlington Arlington, TX, USA <named list [2]> <named list [2]>
#> # ℹ 1 more row然后我们重命名 southwest 和 northeast(矩形的角点),这样我们就可以使用 names_sep 来创建简短但有意义的名称:
locations |>
select(city, formatted_address, geometry) |>
unnest_wider(geometry) |>
select(!location:viewport) |>
unnest_wider(bounds) |>
rename(ne = northeast, sw = southwest) |>
unnest_wider(c(ne, sw), names_sep = "_")
#> # A tibble: 7 × 6
#> city formatted_address ne_lat ne_lng sw_lat sw_lng
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 Houston Houston, TX, USA 30.1 -95.0 29.5 -95.8
#> 2 Washington Washington, USA 49.0 -117. 45.5 -125.
#> 3 Washington Washington, DC, USA 39.0 -76.9 38.8 -77.1
#> 4 New York New York, NY, USA 40.9 -73.7 40.5 -74.3
#> 5 Chicago Chicago, IL, USA 42.0 -87.5 41.6 -87.9
#> 6 Arlington Arlington, TX, USA 32.8 -97.0 32.6 -97.2
#> # ℹ 1 more row注意我们如何通过向 unnest_wider() 提供一个变量名称的向量来同时展开两列。
一旦你找到了到达你感兴趣的组件的路径,你可以使用另一个 tidyr 函数 hoist() 直接提取它们:
如果这些案例研究激发了你对更多现实生活中的矩形化问题的兴趣,你可以在 vignette("rectangling", package = "tidyr") 中看到更多例子。
23.4.4 练习
粗略估计
gh_repos是何时创建的。为什么你只能粗略估计日期?gh_repo的owner列包含大量重复信息,因为每个所有者可以有多个仓库。你能否构建一个owners数据框,其中每个所有者只有一行?(提示:distinct()对list-cols有效吗?)按照用于
titles的步骤,为《权力的游戏》角色的别名 (aliases)、效忠 (allegiances)、书籍 (books) 和电视剧集 (TV series) 创建类似的表。-
逐行解释以下代码。它为什么有趣?为什么它对
got_chars有效,但在一般情况下可能无效?tibble(json = got_chars) |> unnest_wider(json) |> select(id, where(is.list)) |> pivot_longer( where(is.list), names_to = "name", values_to = "value" ) |> unnest_longer(value) 在
gmaps_cities中,address_components包含什么?为什么行与行之间的长度不同?适当地展开它来找出答案。(提示:types似乎总是包含两个元素。使用unnest_wider()是否比unnest_longer()更容易处理?)
23.5 JSON
上一节的所有案例研究都来源于现实世界中捕获的 JSON。JSON 是 JavaScript Object Notation (JavaScript 对象表示法) 的缩写,是大多数 Web API 返回数据的方式。理解它很重要,因为尽管 JSON 和 R 的数据类型非常相似,但并不存在完美的 1 对 1 映射,所以如果出现问题,了解一些关于 JSON 的知识是很有好处的。
23.5.1 数据类型
JSON 是一种简单的格式,设计用于机器轻松读写,而不是人类。它有六种关键的数据类型。其中四种是标量 (scalar):
- 最简单的类型是空值 (
null),它在 R 中扮演与NA相同的角色。它表示数据的缺失。 - 字符串 (string) 很像 R 中的字符串,但必须始终使用双引号。
-
数字 (number) 类似于 R 的数字:它们可以使用整数(例如,123)、小数(例如,123.45)或科学记数法(例如,1.23e3)。JSON 不支持
Inf、-Inf或NaN。 -
布尔值 (boolean) 类似于 R 的
TRUE和FALSE,但使用小写的true和false。
JSON 的字符串、数字和布尔值与 R 的字符、数值和逻辑向量非常相似。主要区别在于 JSON 的标量只能表示单个值。要表示多个值,你需要使用剩下的两种类型之一:数组 (array) 和对象 (object)。
数组和对象都类似于 R 中的列表;区别在于它们是否被命名。数组 就像一个未命名的列表,用 [] 书写。例如 [1, 2, 3] 是一个包含 3 个数字的数组,而 [null, 1, "string", false] 是一个包含空值、数字、字符串和布尔值的数组。对象 就像一个命名的列表,用 {} 书写。名称(在 JSON 术语中称为键 (key))是字符串,因此必须用引号括起来。例如,{"x": 1, "y": 2} 是一个将 x 映射到 1,y 映射到 2 的对象。
请注意,JSON 没有任何表示日期或日期时间的本地方式,因此它们通常作为字符串存储,你需要使用 readr::parse_date() 或 readr::parse_datetime() 将它们转换为正确的数据结构。同样,JSON 表示浮点数的规则有点不精确,所以你有时也会发现数字存储在字符串中。根据需要应用 readr::parse_double() 来获得正确的变量类型。
23.5.2 jsonlite
要将 JSON 转换为 R 的数据结构,我们推荐 Jeroen Ooms 开发的 jsonlite 包。我们将只使用两个 jsonlite 函数:read_json() 和 parse_json()。在实际生活中,你会使用 read_json() 从磁盘读取 JSON 文件。例如,repurrrsive 包也提供了 gh_user 的源数据作为 JSON 文件,你可以用 read_json() 读取它:
# 包内一个 json 文件的路径:
gh_users_json()
#> [1] "C:/Users/14913/AppData/Local/R/win-library/4.5/repurrrsive/extdata/gh_users.json"
# 用 read_json() 读取它
gh_users2 <- read_json(gh_users_json())
# 检查它是否与我们之前使用的数据相同
identical(gh_users, gh_users2)
#> [1] TRUE在本书中,我们还会使用 parse_json(),因为它接受一个包含 JSON 的字符串,这对于生成简单的例子很有用。首先,这里有三个简单的 JSON 数据集,从一个数字开始,然后将几个数字放入一个数组,再将该数组放入一个对象中:
str(parse_json('1'))
#> int 1
str(parse_json('[1, 2, 3]'))
#> List of 3
#> $ : int 1
#> $ : int 2
#> $ : int 3
str(parse_json('{"x": [1, 2, 3]}'))
#> List of 1
#> $ x:List of 3
#> ..$ : int 1
#> ..$ : int 2
#> ..$ : int 3jsonlite 还有另一个重要的函数叫做 fromJSON()。我们在这里不使用它,因为它会执行自动简化 (simplifyVector = TRUE)。这在简单情况下通常效果很好,但我们认为你自己进行矩形化会更好,这样你就确切地知道发生了什么,并且可以更容易地处理最复杂的嵌套结构。
23.5.3 开始矩形化过程
在大多数情况下,JSON 文件包含一个单一的顶层数组,因为它们被设计用来提供关于多个“事物”的数据,例如,多个页面、多个记录或多个结果。在这种情况下,你将以 tibble(json) 开始你的矩形化,以便每个元素都成为一行:
json <- '[
{"name": "John", "age": 34},
{"name": "Susan", "age": 27}
]'
df <- tibble(json = parse_json(json))
df
#> # A tibble: 2 × 1
#> json
#> <list>
#> 1 <named list [2]>
#> 2 <named list [2]>
df |>
unnest_wider(json)
#> # A tibble: 2 × 2
#> name age
#> <chr> <int>
#> 1 John 34
#> 2 Susan 27在更罕见的情况下,JSON 文件由一个单一的顶层 JSON 对象组成,代表一个“事物”。在这种情况下,你需要通过将其包装在一个列表中来启动矩形化过程,然后再将其放入 tibble 中。
json <- '{
"status": "OK",
"results": [
{"name": "John", "age": 34},
{"name": "Susan", "age": 27}
]
}
'
df <- tibble(json = list(parse_json(json)))
df
#> # A tibble: 1 × 1
#> json
#> <list>
#> 1 <named list [2]>
df |>
unnest_wider(json) |>
unnest_longer(results) |>
unnest_wider(results)
#> # A tibble: 2 × 3
#> status name age
#> <chr> <chr> <int>
#> 1 OK John 34
#> 2 OK Susan 27或者,你可以深入到解析后的 JSON 内部,从你真正关心的部分开始:
df <- tibble(results = parse_json(json)$results)
df |>
unnest_wider(results)
#> # A tibble: 2 × 2
#> name age
#> <chr> <int>
#> 1 John 34
#> 2 Susan 2723.5.4 练习
-
将下面的
df_col和df_row进行矩形化。它们代表了在 JSON 中编码数据框的两种方式。json_col <- parse_json(' { "x": ["a", "x", "z"], "y": [10, null, 3] } ') json_row <- parse_json(' [ {"x": "a", "y": 10}, {"x": "x", "y": null}, {"x": "z", "y": 3} ] ') df_col <- tibble(json = list(json_col)) df_row <- tibble(json = json_row)
23.6 总结
在本章中,你学习了什么是列表,如何从 JSON 文件生成它们,以及如何将它们转换为矩形数据框。令人惊讶的是,我们只需要两个新函数:unnest_longer() 用于将列表元素放入行中,unnest_wider() 用于将列表元素放入列中。无论列表列的嵌套有多深,你所需要做的就是重复调用这两个函数。
JSON 是 Web API 返回的最常见的数据格式。如果网站没有 API,但你可以在网站上看到你想要的数据,那该怎么办呢?这就是下一章的主题:网络抓取 (web scraping),从 HTML 网页中提取数据。
这是 RStudio 的一个功能。↩︎