12 逻辑向量
12.1 引言
在本章中,你将学习处理逻辑向量的工具。逻辑向量是最简单的向量类型,因为每个元素只能是三个可能的值之一:TRUE、FALSE 和 NA。在原始数据中很少会遇到逻辑向量,但在几乎每一次分析的过程中,你都会创建和操作它们。
我们将首先讨论创建逻辑向量最常用的方法:使用数值比较。然后,你将学习如何使用布尔代数来组合不同的逻辑向量,以及一些有用的汇总方法。最后,我们将介绍 if_else() 和 case_when(),这是两个非常有用的函数,可以利用逻辑向量进行条件性更改。
12.1.1 先决条件
本章中你将学到的大部分函数都由 R base 提供,所以我们并不需要 tidyverse,但我们仍然会加载它,以便使用 mutate()、filter() 等函数来处理数据框。我们也将继续使用 nycflights13::flights 数据集中的示例。
然而,随着我们开始涉及更多的工具,并不总能找到一个完美的真实示例。因此,我们将开始使用 c() 来创建一些虚拟数据:
x <- c(1, 2, 3, 5, 7, 11, 13)
x * 2
#> [1] 2 4 6 10 14 22 26这样做虽然更容易解释单个函数,但代价是更难看出它如何应用于你的数据问题。只需记住,我们对一个独立向量进行的任何操作,你都可以通过 mutate() 及相关函数对数据框中的变量进行同样的操作。
12.2 比较
创建逻辑向量的一种非常常见的方法是通过数值比较运算符:<、<=、>、>=、!= 和 ==。到目前为止,我们主要是在 filter() 中临时创建逻辑变量——它们被计算、使用,然后被丢弃。例如,下面的筛选器会找出所有在白天出发且大致准点到达的航班:
flights |>
filter(dep_time > 600 & dep_time < 2000 & abs(arr_delay) < 20)
#> # A tibble: 172,286 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 601 600 1 844 850
#> 2 2013 1 1 602 610 -8 812 820
#> 3 2013 1 1 602 605 -3 821 805
#> 4 2013 1 1 606 610 -4 858 910
#> 5 2013 1 1 606 610 -4 837 845
#> 6 2013 1 1 607 607 0 858 915
#> # ℹ 172,280 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …知道这其实是一种简便写法是很有用的,你完全可以使用 mutate() 显式地创建底层的逻辑变量:
flights |>
mutate(
daytime = dep_time > 600 & dep_time < 2000,
approx_ontime = abs(arr_delay) < 20,
.keep = "used"
)
#> # A tibble: 336,776 × 4
#> dep_time arr_delay daytime approx_ontime
#> <int> <dbl> <lgl> <lgl>
#> 1 517 11 FALSE TRUE
#> 2 533 20 FALSE FALSE
#> 3 542 33 FALSE FALSE
#> 4 544 -18 FALSE TRUE
#> 5 554 -25 FALSE FALSE
#> 6 554 12 FALSE TRUE
#> # ℹ 336,770 more rows这对于更复杂的逻辑尤其有用,因为给中间步骤命名能让你的代码更易于阅读,也更容易检查每一步是否计算正确。
总而言之,最初的筛选器等同于:
12.2.1 浮点数比较
注意不要对数值使用 ==。例如,看起来这个向量包含了数字 1 和 2:
但如果你测试它们是否相等,会得到 FALSE:
x == c(1, 2)
#> [1] FALSE FALSE这是怎么回事?计算机使用固定的小数位数来存储数字,所以无法精确表示 1/49 或 sqrt(2),后续的计算会有非常微小的偏差。我们可以通过调用 print() 并使用 digits1 参数来查看确切的值:
print(x, digits = 16)
#> [1] 0.9999999999999999 2.0000000000000004你可以看到为什么 R 默认会对这些数字进行四舍五入;它们确实非常接近你期望的值。
既然你已经明白了 == 为什么会失效,那你该怎么办呢?一个选项是使用 dplyr::near(),它会忽略微小的差异:
12.2.2 缺失值
缺失值代表未知,所以它们是“会传染的”:几乎任何涉及未知值的操作,其结果也将是未知的:
NA > 5
#> [1] NA
10 == NA
#> [1] NA最令人困惑的结果是这一个:
NA == NA
#> [1] NA如果我们人为地提供一些上下文,就最容易理解为什么会这样:
# 我们不知道 Mary 的年龄
age_mary <- NA
# 我们不知道 John 的年龄
age_john <- NA
# Mary 和 John 同龄吗?
age_mary == age_john
#> [1] NA
# 我们不知道!所以,如果你想找出 dep_time 缺失的所有航班,下面的代码是行不通的,因为 dep_time == NA 对每一行都会产生 NA,而 filter() 会自动丢弃缺失值:
flights |>
filter(dep_time == NA)
#> # A tibble: 0 × 19
#> # ℹ 19 variables: year <int>, month <int>, day <int>, dep_time <int>,
#> # sched_dep_time <int>, dep_delay <dbl>, arr_time <int>, …为此,我们需要一个新工具:is.na()。
12.2.3 is.na()
is.na(x) 适用于任何类型的向量,它对缺失值返回 TRUE,对其他所有值返回 FALSE:
我们可以使用 is.na() 来找到 dep_time 缺失的所有行:
flights |>
filter(is.na(dep_time))
#> # A tibble: 8,255 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 NA 1630 NA NA 1815
#> 2 2013 1 1 NA 1935 NA NA 2240
#> 3 2013 1 1 NA 1500 NA NA 1825
#> 4 2013 1 1 NA 600 NA NA 901
#> 5 2013 1 2 NA 1540 NA NA 1747
#> 6 2013 1 2 NA 1620 NA NA 1746
#> # ℹ 8,249 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …is.na() 在 arrange() 中也很有用。arrange() 通常将所有缺失值放在末尾,但你可以通过先按 is.na() 排序来覆盖这个默认行为:
flights |>
filter(month == 1, day == 1) |>
arrange(dep_time)
#> # A tibble: 842 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # ℹ 836 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …
flights |>
filter(month == 1, day == 1) |>
arrange(desc(is.na(dep_time)), dep_time)
#> # A tibble: 842 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 NA 1630 NA NA 1815
#> 2 2013 1 1 NA 1935 NA NA 2240
#> 3 2013 1 1 NA 1500 NA NA 1825
#> 4 2013 1 1 NA 600 NA NA 901
#> 5 2013 1 1 517 515 2 830 819
#> 6 2013 1 1 533 529 4 850 830
#> # ℹ 836 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …我们将在 Chapter 18 中更深入地探讨缺失值。
12.2.4 练习
-
dplyr::near()是如何工作的?输入near查看源代码。sqrt(2)^2是否接近 2? - 结合使用
mutate()、is.na()和count()来描述dep_time、sched_dep_time和dep_delay中的缺失值是如何相互关联的。
12.3 布尔代数
一旦你有了多个逻辑向量,你就可以使用布尔代数将它们组合起来。在 R 中,& 是“与”,| 是“或”,! 是“非”,而 xor() 是“异或”2。例如,df |> filter(!is.na(x)) 会找出 x 不缺失的所有行,而 df |> filter(x < -10 | x > 0) 会找出 x 小于 -10 或大于 0 的所有行。Figure 12.1 展示了完整的布尔运算集合及其工作方式。
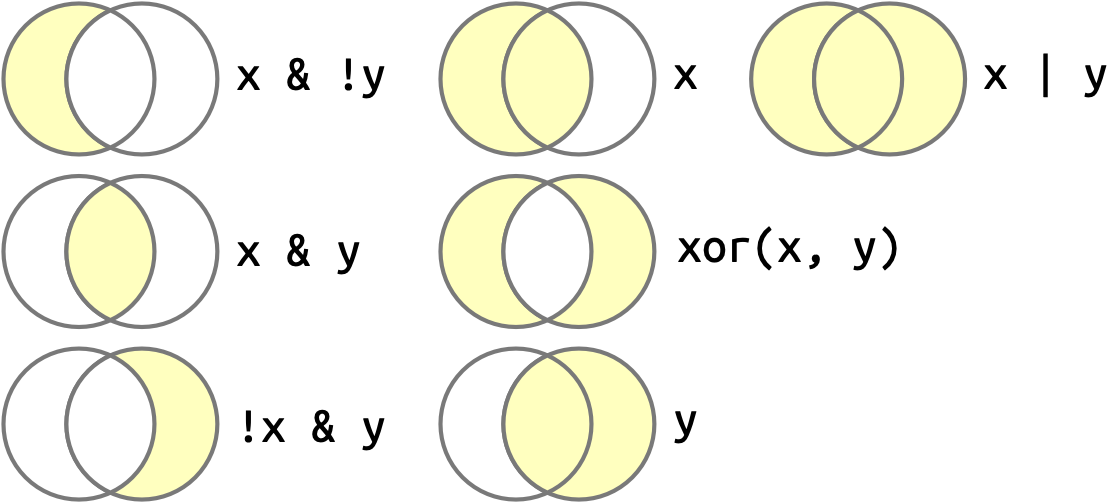
x 是左边的圆,y 是右边的圆, 阴影区域显示了每个运算符选择的部分。
除了 & 和 |,R 还有 && 和 ||。不要在 dplyr 函数中使用它们!这些被称为短路运算符,它们只返回单个 TRUE 或 FALSE。它们对于编程很重要,但对于数据科学则不然。
12.3.1 缺失值
布尔代数中关于缺失值的规则解释起来有点棘手,因为它们初看起来似乎不一致:
要理解发生了什么,可以思考一下 NA | TRUE(NA 或 TRUE)。逻辑向量中的一个缺失值意味着这个值可能是 TRUE 或 FALSE。TRUE | TRUE 和 FALSE | TRUE 都为 TRUE,因为至少有一个是 TRUE。因此 NA | TRUE 也必须是 TRUE,因为 NA 可能是 TRUE 或 FALSE。然而,NA | FALSE 的结果是 NA,因为我们不知道 NA 是 TRUE 还是 FALSE。类似的推理也适用于 &,考虑到 & 要求两个条件都必须满足。因此,NA & TRUE 的结果是 NA,因为 NA 可能是 TRUE 或 FALSE;而 NA & FALSE 的结果是 FALSE,因为至少有一个条件是 FALSE。
12.3.2 运算顺序
请注意,运算顺序不像英语那样。看下面这段代码,它用于查找所有在十一月或十二月出发的航班:
flights |>
filter(month == 11 | month == 12)你可能会想当然地像说英语一样写它:“查找所有在十一月或十二月出发的航班。”:
flights |>
filter(month == 11 | 12)
#> # A tibble: 336,776 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # ℹ 336,770 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …这段代码不会报错,但似乎也没有起作用。这是怎么回事?在这里,R 首先评估 month == 11,创建了一个我们称之为 nov 的逻辑向量。然后它计算 nov | 12。当你对一个逻辑运算符使用数字时,它会把除了 0 之外的所有数都转换为 TRUE,所以这等价于 nov | TRUE,结果将永远是 TRUE,因此每一行都会被选中:
flights |>
mutate(
nov = month == 11,
final = nov | 12,
.keep = "used"
)
#> # A tibble: 336,776 × 3
#> month nov final
#> <int> <lgl> <lgl>
#> 1 1 FALSE TRUE
#> 2 1 FALSE TRUE
#> 3 1 FALSE TRUE
#> 4 1 FALSE TRUE
#> 5 1 FALSE TRUE
#> 6 1 FALSE TRUE
#> # ℹ 336,770 more rows
12.3.3 %in%
避免 == 和 | 顺序出错的一个简单方法是使用 %in%。x %in% y 返回一个与 x 长度相同的逻辑向量,当 x 中的值出现在 y 中的任何位置时,该向量对应位置的值为 TRUE。
因此,要查找所有十一月和十二月的航班,我们可以这样写:
注意,%in% 对于 NA 的处理规则与 == 不同,因为 NA %in% NA 的结果是 TRUE。
这可以成为一个有用的简便写法:
flights |>
filter(dep_time %in% c(NA, 0800))
#> # A tibble: 8,803 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 800 800 0 1022 1014
#> 2 2013 1 1 800 810 -10 949 955
#> 3 2013 1 1 NA 1630 NA NA 1815
#> 4 2013 1 1 NA 1935 NA NA 2240
#> 5 2013 1 1 NA 1500 NA NA 1825
#> 6 2013 1 1 NA 600 NA NA 901
#> # ℹ 8,797 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …12.3.4 练习
- 找出所有
arr_delay缺失但dep_delay不缺失的航班。找出所有arr_time和sched_arr_time都不缺失,但arr_delay缺失的航班。 - 有多少航班的
dep_time是缺失的?这些行中还有哪些其他变量是缺失的?这些行可能代表什么? - 假设缺失的
dep_time意味着航班被取消了,查看每天被取消航班的数量。是否存在某种模式?被取消航班的比例与未取消航班的平均延误之间是否存在联系?
12.4 汇总
以下各节描述了一些用于汇总逻辑向量的有用技术。除了专门用于逻辑向量的函数外,你也可以使用那些适用于数值向量的函数。
12.4.1 逻辑汇总
有两个主要的逻辑汇总函数:any() 和 all()。any(x) 相当于 |;如果 x 中有任何 TRUE,它将返回 TRUE。all(x) 相当于 &;只有当 x 的所有值都是 TRUE 时,它才会返回 TRUE。与大多数汇总函数一样,你可以通过 na.rm = TRUE 来忽略缺失值。
例如,我们可以使用 all() 和 any() 来查看是否每天的所有航班出发延误都不超过一小时,或者是否有任何航班到达延误达到五小时或更长。并且,使用 group_by() 允许我们按天来进行这种分析:
flights |>
group_by(year, month, day) |>
summarize(
all_delayed = all(dep_delay <= 60, na.rm = TRUE),
any_long_delay = any(arr_delay >= 300, na.rm = TRUE),
.groups = "drop"
)
#> # A tibble: 365 × 5
#> year month day all_delayed any_long_delay
#> <int> <int> <int> <lgl> <lgl>
#> 1 2013 1 1 FALSE TRUE
#> 2 2013 1 2 FALSE TRUE
#> 3 2013 1 3 FALSE FALSE
#> 4 2013 1 4 FALSE FALSE
#> 5 2013 1 5 FALSE TRUE
#> 6 2013 1 6 FALSE FALSE
#> # ℹ 359 more rows然而,在大多数情况下,any() 和 all() 有点过于粗略,如果能获得更多关于有多少值是 TRUE 或 FALSE 的细节会更好。这就引出了数值汇总。
12.4.2 逻辑向量的数值汇总
当你在数值上下文中使用逻辑向量时,TRUE 会变成 1,FALSE 会变成 0。这使得 sum() 和 mean() 在处理逻辑向量时非常有用,因为 sum(x) 给出 TRUE 的数量,而 mean(x) 给出 TRUE 的比例(因为 mean() 就是 sum() 除以 length())。
例如,这可以让我们看到出发延误不超过一小时的航班比例,以及到达延误五小时或更长时间的航班数量:
flights |>
group_by(year, month, day) |>
summarize(
proportion_delayed = mean(dep_delay <= 60, na.rm = TRUE),
count_long_delay = sum(arr_delay >= 300, na.rm = TRUE),
.groups = "drop"
)
#> # A tibble: 365 × 5
#> year month day proportion_delayed count_long_delay
#> <int> <int> <int> <dbl> <int>
#> 1 2013 1 1 0.939 3
#> 2 2013 1 2 0.914 3
#> 3 2013 1 3 0.941 0
#> 4 2013 1 4 0.953 0
#> 5 2013 1 5 0.964 1
#> 6 2013 1 6 0.959 0
#> # ℹ 359 more rows12.4.3 逻辑子集
在汇总中,逻辑向量还有最后一个用途:你可以使用一个逻辑向量来将单个变量筛选到感兴趣的子集。这利用了 R base 的 [(读作 subset)运算符,你将在 Section 27.2 中学到更多相关内容。
假设我们想查看仅仅是那些实际延误了的航班的平均延误。一种方法是先筛选出航班,然后计算平均延误:
flights |>
filter(arr_delay > 0) |>
group_by(year, month, day) |>
summarize(
behind = mean(arr_delay),
n = n(),
.groups = "drop"
)
#> # A tibble: 365 × 5
#> year month day behind n
#> <int> <int> <int> <dbl> <int>
#> 1 2013 1 1 32.5 461
#> 2 2013 1 2 32.0 535
#> 3 2013 1 3 27.7 460
#> 4 2013 1 4 28.3 297
#> 5 2013 1 5 22.6 238
#> 6 2013 1 6 24.4 381
#> # ℹ 359 more rows这行得通,但如果我们还想计算那些提早到达航班的平均延误呢?我们就需要执行一个单独的筛选步骤,然后想办法将这两个数据框合并在一起3。相反,你可以使用 [ 来执行内联筛选:arr_delay[arr_delay > 0] 将只产生正的到达延误值。
这样就会得到:
flights |>
group_by(year, month, day) |>
summarize(
behind = mean(arr_delay[arr_delay > 0], na.rm = TRUE),
ahead = mean(arr_delay[arr_delay < 0], na.rm = TRUE),
n = n(),
.groups = "drop"
)
#> # A tibble: 365 × 6
#> year month day behind ahead n
#> <int> <int> <int> <dbl> <dbl> <int>
#> 1 2013 1 1 32.5 -12.5 842
#> 2 2013 1 2 32.0 -14.3 943
#> 3 2013 1 3 27.7 -18.2 914
#> 4 2013 1 4 28.3 -17.0 915
#> 5 2013 1 5 22.6 -14.0 720
#> 6 2013 1 6 24.4 -13.6 832
#> # ℹ 359 more rows同时请注意组大小的差异:在第一个代码块中,n() 给出的是每天延误的航班数量;在第二个代码块中,n() 给出的是总航班数。
12.4.4 练习
12.5 条件转换
逻辑向量最强大的特性之一是它们在条件转换中的应用,即对条件 x 做一件事,对条件 y 做另一件事。有两个重要的工具可以实现这一点:if_else() 和 case_when()。
12.5.1 if_else()
如果你想在条件为 TRUE 时使用一个值,而在条件为 FALSE 时使用另一个值,你可以使用 dplyr::if_else()4。你总是会使用 if_else() 的前三个参数。第一个参数 condition 是一个逻辑向量;第二个参数 true 给出条件为真时的输出;第三个参数 false 给出条件为假时的输出。
我们从一个简单的例子开始,将一个数值向量标记为 “+ve” (正数) 或 “-ve” (负数):
还有一个可选的第四个参数 missing,如果输入是 NA,就会使用这个值:
if_else(x > 0, "+ve", "-ve", "???")
#> [1] "-ve" "-ve" "-ve" "-ve" "+ve" "+ve" "+ve" "???"你也可以为 true 和 false 参数使用向量。例如,这允许我们创建一个 abs() 的最小化实现:
if_else(x < 0, -x, x)
#> [1] 3 2 1 0 1 2 3 NA到目前为止,所有的参数都使用了相同的向量,但你当然可以混合搭配。例如,你可以像这样实现一个 coalesce() 的简单版本:
你可能已经注意到我们上面标签示例中的一个小瑕疵:零既不是正数也不是负数。我们可以通过添加一个额外的 if_else() 来解决这个问题:
这已经有点难读了,你可以想象如果你有更多的条件,情况只会变得更糟。此时,你可以转而使用 dplyr::case_when()。
12.5.2 case_when()
dplyr 的 case_when() 受到 SQL 的 CASE 语句的启发,提供了一种为不同条件执行不同计算的灵活方式。它有一种特殊的语法,不幸的是,它看起来与你在 tidyverse 中使用的其他任何东西都不一样。它接受形如 condition ~ output 的配对。condition 必须是一个逻辑向量;当它为 TRUE 时,将使用 output。
这意味着我们可以像下面这样重新创建我们之前的嵌套 if_else():
这代码量更多,但也更明确。
为了解释 case_when() 的工作原理,让我们来探讨一些更简单的情况。如果没有一个条件匹配,输出会得到一个 NA:
case_when(
x < 0 ~ "-ve",
x > 0 ~ "+ve"
)
#> [1] "-ve" "-ve" "-ve" NA "+ve" "+ve" "+ve" NA如果你想创建一个“默认”或“全收”的值,可以使用 .default:
case_when(
x < 0 ~ "-ve",
x > 0 ~ "+ve",
.default = "???"
)
#> [1] "-ve" "-ve" "-ve" "???" "+ve" "+ve" "+ve" "???"并且请注意,如果多个条件匹配,只有第一个会被使用:
case_when(
x > 0 ~ "+ve",
x > 2 ~ "big"
)
#> [1] NA NA NA NA "+ve" "+ve" "+ve" NA就像 if_else() 一样,你可以在 ~ 的两边都使用变量,并且可以根据你的问题需要混合搭配变量。例如,我们可以使用 case_when() 为到达延误提供一些人类可读的标签:
flights |>
mutate(
status = case_when(
is.na(arr_delay) ~ "cancelled",
arr_delay < -30 ~ "very early",
arr_delay < -15 ~ "early",
abs(arr_delay) <= 15 ~ "on time",
arr_delay < 60 ~ "late",
arr_delay < Inf ~ "very late",
),
.keep = "used"
)
#> # A tibble: 336,776 × 2
#> arr_delay status
#> <dbl> <chr>
#> 1 11 on time
#> 2 20 late
#> 3 33 late
#> 4 -18 early
#> 5 -25 early
#> 6 12 on time
#> # ℹ 336,770 more rows在编写这类复杂的 case_when() 语句时要小心;我前两次的尝试混合使用了 < 和 >,结果不小心创建了重叠的条件。
12.5.3 兼容的类型
请注意,if_else() 和 case_when() 都要求输出中的类型是兼容的。如果它们不兼容,你会看到类似这样的错误:
总的来说,相对较少的类型是兼容的,因为自动将一种类型的向量转换为另一种是常见的错误来源。以下是兼容的最重要的几种情况:
- 数值和逻辑向量是兼容的,正如我们在 Section 12.4.2 中讨论的那样。
- 字符串和因子 (Chapter 16) 是兼容的,因为你可以把因子看作是具有一组受限值的字符串。
- 日期和日期时间,我们将在 Chapter 17 中讨论,是兼容的,因为你可以把日期看作是日期时间的一种特殊情况。
-
NA,技术上是一个逻辑向量,与所有类型都兼容,因为每个向量都有某种方式来表示缺失值。
我们不期望你记住这些规则,但它们应该会随着时间的推移成为你的第二天性,因为它们在整个 tidyverse 中都是一致应用的。
12.5.4 练习
一个数如果是偶数,那么它能被 2 整除,在 R 中你可以用
x %% 2 == 0来判断。利用这个事实和if_else()来判断 0 到 20 之间的每个数是奇数还是偶数。给定一个像
x <- c("Monday", "Saturday", "Wednesday")这样的日期向量,使用一个if_else()语句将它们标记为周末或工作日。使用
if_else()来计算一个名为x的数值向量的绝对值。编写一个
case_when()语句,使用flights数据集中的month和day列来标记一些重要的美国节日(例如,元旦、7月4日独立日、感恩节和圣诞节)。首先创建一个值为TRUE或FALSE的逻辑列,然后创建一个字符列,该列要么给出节日的名称,要么是NA。
12.6 总结
逻辑向量的定义很简单,因为每个值必须是 TRUE、FALSE 或 NA 之一。但逻辑向量提供了巨大的能力。在本章中,你学习了如何使用 >、<、<=、>=、==、!= 和 is.na() 创建逻辑向量,如何使用 !、& 和 | 组合它们,以及如何使用 any()、all()、sum() 和 mean() 汇总它们。你还学习了强大的 if_else() 和 case_when() 函数,它们允许你根据逻辑向量的值返回不同的结果。
在接下来的章节中,我们将一次又一次地看到逻辑向量。例如,在 Chapter 14 中,你将学习 str_detect(x, pattern),它返回一个逻辑向量,对于 x 中匹配 pattern 的元素为 TRUE;在 Chapter 17 中,你将通过比较日期和时间来创建逻辑向量。但现在,我们将转向下一个最重要的向量类型:数值向量。
R 通常会为你调用 print(即
x是print(x)的简写),但如果你想提供其他参数,显式调用它会很有用。↩︎也就是说,如果 x 为真,或者 y 为真,但不是两者都为真,那么
xor(x, y)就为真。这与我们在英语中通常使用“or”的方式类似。“两者都”通常不是“你想要冰淇淋还是蛋糕?”这个问题的可接受答案。↩︎我们将在 Chapter 19 中讨论这个问题。↩︎
dplyr 的
if_else()与 R base 的ifelse()非常相似。if_else()相对于ifelse()有两个主要优点:你可以选择如何处理缺失值,并且如果你的变量类型不兼容,if_else()更有可能给出有意义的错误信息。↩︎