25 函数
25.1 引言
提升你作为数据科学家影响力的最佳途径之一就是编写函数。函数能让你以比复制粘贴更强大、更通用的方式自动化处理常见任务。与复制粘贴相比,编写函数有四大优势:
你可以给函数起一个富有表现力的名字,让你的代码更易于理解。
当需求变化时,你只需要在一个地方更新代码,而不是多处。
你消除了在复制粘贴时可能出现的偶然错误(例如,在一个地方更新了变量名,但在另一个地方却没有)。
它让你更容易在不同项目间重用代码,从而随着时间的推移提高你的生产力。
一个很好的经验法则是,当你复制粘贴一个代码块超过两次(即你现在有了同一代码的三个副本)时,就应该考虑编写一个函数。在本章中,你将学习三种有用的函数类型:
- 向量函数:接收一个或多个向量作为输入,并返回一个向量作为输出。
- 数据框函数:接收一个数据框作为输入,并返回一个数据框作为输出。
- 绘图函数:接收一个数据框作为输入,并返回一个绘图作为输出。
每个部分都包含许多示例,以帮助你归纳所见的模式。没有 Twitter 上朋友们的帮助,这些示例是不可能完成的,我们鼓励你点击注释中的链接查看原始灵感。你可能还想阅读关于通用函数和绘图函数的原始激励推文,以看到更多函数。
25.1.1 前提条件
我们将封装来自 tidyverse 各处的多种函数。我们还将使用 nycflights13 作为熟悉的数据源来应用我们的函数。
25.2 向量函数
我们从向量函数开始:这类函数接收一个或多个向量并返回一个向量结果。例如,看看这段代码。它做了什么?
df <- tibble(
a = rnorm(5),
b = rnorm(5),
c = rnorm(5),
d = rnorm(5),
)
df |> mutate(
a = (a - min(a, na.rm = TRUE)) /
(max(a, na.rm = TRUE) - min(a, na.rm = TRUE)),
b = (b - min(a, na.rm = TRUE)) /
(max(b, na.rm = TRUE) - min(b, na.rm = TRUE)),
c = (c - min(c, na.rm = TRUE)) /
(max(c, na.rm = TRUE) - min(c, na.rm = TRUE)),
d = (d - min(d, na.rm = TRUE)) /
(max(d, na.rm = TRUE) - min(d, na.rm = TRUE)),
)
#> # A tibble: 5 × 4
#> a b c d
#> <dbl> <dbl> <dbl> <dbl>
#> 1 0.339 0.387 0.291 0
#> 2 0.880 -0.613 0.611 0.557
#> 3 0 -0.0833 1 0.752
#> 4 0.795 -0.0822 0 1
#> 5 1 -0.0952 0.580 0.394你或许能琢磨出来,这是将每一列重新缩放到 0 到 1 的范围内。但你发现那个错误了吗?Hadley 在写这段代码时,复制粘贴时犯了个错误,忘记了把一个 a 改成 b。防止这类错误的发生是学习如何编写函数的一个很好的理由。
25.2.1 编写一个函数
要编写一个函数,你首先需要分析你重复的代码,找出哪些部分是固定不变的,哪些部分是变化的。如果我们把上面的代码从 mutate() 中拿出来,模式会看得更清楚一些,因为现在每次重复都只有一行:
为了让这更清晰,我们可以用 █ 替换变化的部分:
(█ - min(█, na.rm = TRUE)) / (max(█, na.rm = TRUE) - min(█, na.rm = TRUE))要把它变成一个函数,你需要三样东西:
一个名字。这里我们用
rescale01,因为这个函数将一个向量重新缩放到 0 和 1 之间。参数 (arguments)。参数是在不同调用中变化的东西,我们上面的分析告诉我们只有一个。我们称它为
x,因为这是数值向量的常规名称。函数体 (body)。函数体是在所有调用中重复的代码。
然后你按照这个模板创建一个函数:
name <- function(arguments) {
body
}对于这个例子,就得到了:
此时,你可能会用一些简单的输入来测试,以确保你正确地捕捉了逻辑:
然后你可以将对 mutate() 的调用重写为:
df |> mutate(
a = rescale01(a),
b = rescale01(b),
c = rescale01(c),
d = rescale01(d),
)
#> # A tibble: 5 × 4
#> a b c d
#> <dbl> <dbl> <dbl> <dbl>
#> 1 0.339 1 0.291 0
#> 2 0.880 0 0.611 0.557
#> 3 0 0.530 1 0.752
#> 4 0.795 0.531 0 1
#> 5 1 0.518 0.580 0.394(在 Chapter 26 中,你将学习如何使用 across() 来进一步减少重复,这样你只需要 df |> mutate(across(a:d, rescale01)))。
25.2.2 改进我们的函数
你可能会注意到 rescale01() 函数做了一些不必要的工作 — 与其计算两次 min() 和一次 max(),我们不如用 range() 一步计算出最小值和最大值:
rescale01 <- function(x) {
rng <- range(x, na.rm = TRUE)
(x - rng[1]) / (rng[2] - rng[1])
}或者你可以用一个包含无穷大值的向量来试试这个函数:
x <- c(1:10, Inf)
rescale01(x)
#> [1] 0 0 0 0 0 0 0 0 0 0 NaN这个结果不是特别有用,所以我们可以让 range() 忽略无穷大值:
rescale01 <- function(x) {
rng <- range(x, na.rm = TRUE, finite = TRUE)
(x - rng[1]) / (rng[2] - rng[1])
}
rescale01(x)
#> [1] 0.0000000 0.1111111 0.2222222 0.3333333 0.4444444 0.5555556 0.6666667
#> [8] 0.7777778 0.8888889 1.0000000 Inf这些改动展示了函数的一个重要好处:因为我们把重复的代码移到了一个函数里,我们只需要在一个地方做改动。
25.2.3 变换函数
现在你已经掌握了函数的基本概念,让我们来看一大堆例子。我们将从“变换 (mutate)”函数开始,即那些在 mutate() 和 filter() 内部工作得很好的函数,因为它们返回的输出与输入长度相同。
让我们从 rescale01() 的一个简单变体开始。也许你想要计算 Z 分数 (Z-score),将一个向量重新缩放,使其均值为零,标准差为一:
或者,你可能想封装一个简单的 case_when() 并给它一个有用的名字。例如,这个 clamp() 函数确保一个向量的所有值都介于一个最小值和一个最大值之间:
clamp <- function(x, min, max) {
case_when(
x < min ~ min,
x > max ~ max,
.default = x
)
}
clamp(1:10, min = 3, max = 7)
#> [1] 3 3 3 4 5 6 7 7 7 7当然,函数不只适用于数值变量。你可能想做一些重复的字符串操作。也许你需要将第一个字符大写:
first_upper <- function(x) {
str_sub(x, 1, 1) <- str_to_upper(str_sub(x, 1, 1))
x
}
first_upper("hello")
#> [1] "Hello"或者,你可能想在将字符串转换为数字之前,从中剥离百分号、逗号和美元符号:
# https://twitter.com/NVlabormarket/status/1571939851922198530
clean_number <- function(x) {
is_pct <- str_detect(x, "%")
num <- x |>
str_remove_all("%") |>
str_remove_all(",") |>
str_remove_all(fixed("$")) |>
as.numeric()
if_else(is_pct, num / 100, num)
}
clean_number("$12,300")
#> [1] 12300
clean_number("45%")
#> [1] 0.45有时候你的函数会高度专用于某个数据分析步骤。例如,如果你有一堆变量将缺失值记录为 997、998 或 999,你可能想写一个函数来将它们替换为 NA:
我们专注于接收单个向量的例子,因为我们认为它们是最常见的。但是,你的函数没有理由不能接收多个向量输入。
25.2.4 摘要函数
另一个重要的向量函数家族是摘要函数 (summary functions),即在 summarize() 中使用并返回单个值的函数。有时,这可能只是设置一个或两个默认参数的问题:
commas <- function(x) {
str_flatten(x, collapse = ", ", last = " and ")
}
commas(c("cat", "dog", "pigeon"))
#> [1] "cat, dog and pigeon"或者你可能想封装一个简单的计算,比如变异系数 (coefficient of variation),它用标准差除以均值:
或者你只是想通过给一个常见的模式起一个好记的名字来让它更容易记住:
你也可以编写具有多个向量输入的函数。例如,也许你想计算平均绝对百分比误差 (mean absolute percentage error),以帮助你比较模型预测值与实际值:
一旦你开始编写函数,有两个 RStudio 快捷键非常有用:
要查找你编写的函数的定义,将光标放在函数名上,然后按
F2。要快速跳转到一个函数,按
Ctrl + .打开模糊文件和函数查找器,然后输入你函数名的前几个字母。你也可以用它来导航到文件、Quarto 章节等,使其成为一个非常方便的导航工具。
25.2.5 练习
-
练习将以下代码片段转换成函数。思考每个函数的作用是什么?你会怎么称呼它?它需要多少个参数?
在
rescale01()的第二个变体中,无穷大值保持不变。你能否重写rescale01(),使得-Inf映射到 0,而Inf映射到 1?给定一个出生日期向量,编写一个函数来计算以年为单位的年龄。
编写你自己的函数来计算一个数值向量的方差和偏度。你可以在维基百科或其他地方查找定义。
编写
both_na(),一个摘要函数,它接收两个相同长度的向量,并返回两个向量中在相同位置上都为NA的数量。-
阅读文档,弄清楚以下函数的作用。为什么它们虽然很短,但仍然很有用?
is_directory <- function(x) { file.info(x)$isdir } is_readable <- function(x) { file.access(x, 4) == 0 }
25.3 数据框函数
向量函数对于提取在 dplyr 动词内部重复的代码很有用。但你通常也会重复动词本身,尤其是在一个大型的管道中。当你注意到自己多次复制粘贴多个动词时,你可能会考虑编写一个数据框函数。数据框函数的工作方式类似于 dplyr 动词:它们接收一个数据框作为第一个参数,一些额外的参数来说明如何处理它,并返回一个数据框或一个向量。
为了让你能够编写使用 dplyr 动词的函数,我们将首先向你介绍间接性 (indirection) 的挑战,以及如何通过拥抱 (embracing),即 {{ }} 来克服它。掌握了这一理论之后,我们将向你展示一系列例子,来说明你可以用它做什么。
25.3.1 间接性与整洁求值
当你开始编写使用 dplyr 动词的函数时,你很快就会遇到间接性问题。让我们用一个非常简单的函数 grouped_mean() 来说明这个问题。这个函数的目的是计算按 group_var 分组后 mean_var 的均值:
如果我们尝试使用它,会得到一个错误:
diamonds |> grouped_mean(cut, carat)
#> Error in `group_by()`:
#> ! Must group by variables found in `.data`.
#> ✖ Column `group_var` is not found.为了让问题更清晰,我们可以使用一个虚构的数据框:
df <- tibble(
mean_var = 1,
group_var = "g",
group = 1,
x = 10,
y = 100
)
df |> grouped_mean(group, x)
#> # A tibble: 1 × 2
#> group_var `mean(mean_var)`
#> <chr> <dbl>
#> 1 g 1
df |> grouped_mean(group, y)
#> # A tibble: 1 × 2
#> group_var `mean(mean_var)`
#> <chr> <dbl>
#> 1 g 1无论我们如何调用 grouped_mean(),它总是执行 df |> group_by(group_var) |> summarize(mean(mean_var)),而不是 df |> group_by(group) |> summarize(mean(x)) 或 df |> group_by(group) |> summarize(mean(y))。这是一个间接性问题,它的出现是因为 dplyr 使用整洁求值 (tidy evaluation) 来允许你引用数据框内的变量名而无需任何特殊处理。
整洁求值在 95% 的情况下都很棒,因为它使你的数据分析非常简洁,你永远不必说一个变量来自哪个数据框;从上下文中可以很明显地看出来。整洁求值的缺点在于,当我们想把重复的 tidyverse 代码封装成函数时。在这里,我们需要一种方法告诉 group_by() 和 summarize() 不要把 group_var 和 mean_var 当作变量的字面名称,而是查看它们内部,找到我们实际想用的变量。
整洁求值为这个问题提供了一个解决方案,叫做拥抱 (embracing) 🤗。拥抱一个变量意味着用大括号把它包起来,例如 var 变成 {{ var }}。拥抱一个变量会告诉 dplyr 使用存储在参数内的值,而不是把参数本身当作字面上的变量名。记住正在发生什么的一个方法是把 {{ }} 想象成在看一条隧道 — {{ var }} 会让 dplyr 函数查看 var 的内部,而不是寻找一个名为 var 的变量。
所以,要让 grouped_mean() 工作,我们需要用 {{ }} 把 group_var 和 mean_var 包围起来:
成功了!
25.3.2 何时拥抱?
所以,编写数据框函数的关键挑战是弄清楚哪些参数需要被拥抱。幸运的是,这很容易,因为你可以从文档中查到 😄。在文档中有两个术语需要注意,它们对应于整洁求值最常见的两种子类型:
数据掩码 (Data-masking):用于像
arrange()、filter()和summarize()这样用变量进行计算的函数中。整洁选择 (Tidy-selection):用于像
select()、relocate()和rename()这样选择变量的函数中。
对于许多常用函数,你关于哪些参数使用整洁求值的直觉应该是准确的 — 只需思考你是否可以进行计算(例如,x + 1)或选择(例如,a:x)。
在接下来的部分中,我们将探讨一旦你理解了拥抱,你可能会编写的各种方便函数。
25.3.3 常见用例
如果你在进行初步数据探索时经常执行同一组摘要计算,你可能会考虑将它们封装在一个辅助函数中:
summary6 <- function(data, var) {
data |> summarize(
min = min({{ var }}, na.rm = TRUE),
mean = mean({{ var }}, na.rm = TRUE),
median = median({{ var }}, na.rm = TRUE),
max = max({{ var }}, na.rm = TRUE),
n = n(),
n_miss = sum(is.na({{ var }})),
.groups = "drop"
)
}
diamonds |> summary6(carat)
#> # A tibble: 1 × 6
#> min mean median max n n_miss
#> <dbl> <dbl> <dbl> <dbl> <int> <int>
#> 1 0.2 0.798 0.7 5.01 53940 0(每当你将 summarize() 封装在一个辅助函数中时,我们认为设置 .groups = "drop" 是一个好习惯,这样既可以避免消息提示,又能使数据处于未分组状态。)
这个函数的好处在于,因为它封装了 summarize(),你可以在分组数据上使用它:
diamonds |>
group_by(cut) |>
summary6(carat)
#> # A tibble: 5 × 7
#> cut min mean median max n n_miss
#> <ord> <dbl> <dbl> <dbl> <dbl> <int> <int>
#> 1 Fair 0.22 1.05 1 5.01 1610 0
#> 2 Good 0.23 0.849 0.82 3.01 4906 0
#> 3 Very Good 0.2 0.806 0.71 4 12082 0
#> 4 Premium 0.2 0.892 0.86 4.01 13791 0
#> 5 Ideal 0.2 0.703 0.54 3.5 21551 0此外,由于 summarize 的参数是数据掩码的,所以 summary6() 的 var 参数也是。这意味着你也可以对计算出的变量进行摘要:
diamonds |>
group_by(cut) |>
summary6(log10(carat))
#> # A tibble: 5 × 7
#> cut min mean median max n n_miss
#> <ord> <dbl> <dbl> <dbl> <dbl> <int> <int>
#> 1 Fair -0.658 -0.0273 0 0.700 1610 0
#> 2 Good -0.638 -0.133 -0.0862 0.479 4906 0
#> 3 Very Good -0.699 -0.164 -0.149 0.602 12082 0
#> 4 Premium -0.699 -0.125 -0.0655 0.603 13791 0
#> 5 Ideal -0.699 -0.225 -0.268 0.544 21551 0要对多个变量进行摘要,你需要等到 Section 26.2,在那里你将学习如何使用 across()。
另一个流行的 summarize() 辅助函数是 count() 的一个版本,它也计算比例:
# https://twitter.com/Diabb6/status/1571635146658402309
count_prop <- function(df, var, sort = FALSE) {
df |>
count({{ var }}, sort = sort) |>
mutate(prop = n / sum(n))
}
diamonds |> count_prop(clarity)
#> # A tibble: 8 × 3
#> clarity n prop
#> <ord> <int> <dbl>
#> 1 I1 741 0.0137
#> 2 SI2 9194 0.170
#> 3 SI1 13065 0.242
#> 4 VS2 12258 0.227
#> 5 VS1 8171 0.151
#> 6 VVS2 5066 0.0939
#> # ℹ 2 more rows这个函数有三个参数:df、var 和 sort,只有 var 需要被拥抱,因为它被传递给 count(),而 count() 对所有变量都使用数据掩码。注意,我们为 sort 使用了默认值,这样如果用户不提供自己的值,它将默认为 FALSE。
或者,你可能想为数据的子集找到一个变量的已排序的唯一值。与其提供一个变量和一个值来进行筛选,我们将允许用户提供一个条件:
这里我们拥抱 condition 是因为它被传递给 filter(),拥抱 var 是因为它被传递给 distinct() 和 arrange()。
我们把所有这些例子都设置为接收一个数据框作为第一个参数,但如果你反复处理相同的数据,将其硬编码可能是有意义的。例如,下面的函数总是处理 flights 数据集,并且总是选择 time_hour、carrier 和 flight,因为它们构成了可以识别一行的复合主键。
25.3.4 数据掩码 vs. 整洁选择
有时你想在一个使用数据掩码的函数内部选择变量。例如,假设你想写一个 count_missing() 来计算行中缺失观测值的数量。你可能会尝试写成这样:
count_missing <- function(df, group_vars, x_var) {
df |>
group_by({{ group_vars }}) |>
summarize(
n_miss = sum(is.na({{ x_var }})),
.groups = "drop"
)
}
flights |>
count_missing(c(year, month, day), dep_time)
#> Error in `group_by()`:
#> ℹ In argument: `c(year, month, day)`.
#> Caused by error:
#> ! `c(year, month, day)` must be size 336776 or 1, not 1010328.这不起作用,因为 group_by() 使用数据掩码,而不是整洁选择。我们可以通过使用方便的 pick() 函数来解决这个问题,它允许你在数据掩码函数内部使用整洁选择:
count_missing <- function(df, group_vars, x_var) {
df |>
group_by(pick({{ group_vars }})) |>
summarize(
n_miss = sum(is.na({{ x_var }})),
.groups = "drop"
)
}
flights |>
count_missing(c(year, month, day), dep_time)
#> # A tibble: 365 × 4
#> year month day n_miss
#> <int> <int> <int> <int>
#> 1 2013 1 1 4
#> 2 2013 1 2 8
#> 3 2013 1 3 10
#> 4 2013 1 4 6
#> 5 2013 1 5 3
#> 6 2013 1 6 1
#> # ℹ 359 more rowspick() 的另一个方便用法是制作一个二维的计数表。这里我们使用 rows 和 columns 中的所有变量进行计数,然后使用 pivot_wider() 将计数重新排列成一个网格:
# https://twitter.com/pollicipes/status/1571606508944719876
count_wide <- function(data, rows, cols) {
data |>
count(pick(c({{ rows }}, {{ cols }}))) |>
pivot_wider(
names_from = {{ cols }},
values_from = n,
names_sort = TRUE,
values_fill = 0
)
}
diamonds |> count_wide(c(clarity, color), cut)
#> # A tibble: 56 × 7
#> clarity color Fair Good `Very Good` Premium Ideal
#> <ord> <ord> <int> <int> <int> <int> <int>
#> 1 I1 D 4 8 5 12 13
#> 2 I1 E 9 23 22 30 18
#> 3 I1 F 35 19 13 34 42
#> 4 I1 G 53 19 16 46 16
#> 5 I1 H 52 14 12 46 38
#> 6 I1 I 34 9 8 24 17
#> # ℹ 50 more rows虽然我们的例子主要集中在 dplyr 上,但整洁求值也支撑着 tidyr,如果你查看 pivot_wider() 的文档,你会看到 names_from 使用了整洁选择。
25.3.5 练习
-
使用
nycflights13中的数据集,编写一个函数:-
找到所有被取消(即
is.na(arr_time))或延误超过一小时的航班。flights |> filter_severe() -
计算被取消的航班数量和延误超过一小时的航班数量。
flights |> group_by(dest) |> summarize_severe() -
找到所有被取消或延误超过用户提供的小时数的航班:
flights |> filter_severe(hours = 2) -
对天气进行摘要,计算用户提供的变量的最小值、平均值和最大值:
weather |> summarize_weather(temp) -
将用户提供的、使用时钟时间(例如
dep_time、arr_time等)的变量转换为十进制时间(即 小时 + (分钟 / 60))。flights |> standardize_time(sched_dep_time)
-
对于以下每个函数,列出所有使用整洁求值的参数,并描述它们是使用数据掩码还是整洁选择:
distinct()、count()、group_by()、rename_with()、slice_min()、slice_sample()。-
泛化以下函数,以便你可以提供任意数量的变量进行计数。
25.4 绘图函数
你可能想要返回一个绘图,而不是一个数据框。幸运的是,你可以在 ggplot2 中使用相同的技术,因为 aes() 是一个数据掩码函数。例如,想象你正在制作很多直方图:
diamonds |>
ggplot(aes(x = carat)) +
geom_histogram(binwidth = 0.1)
diamonds |>
ggplot(aes(x = carat)) +
geom_histogram(binwidth = 0.05)如果你能把这个封装成一个直方图函数,那不是很好吗?一旦你知道 aes() 是一个数据掩码函数并且你需要拥抱,这就易如反掌了:
histogram <- function(df, var, binwidth = NULL) {
df |>
ggplot(aes(x = {{ var }})) +
geom_histogram(binwidth = binwidth)
}
diamonds |> histogram(carat, 0.1)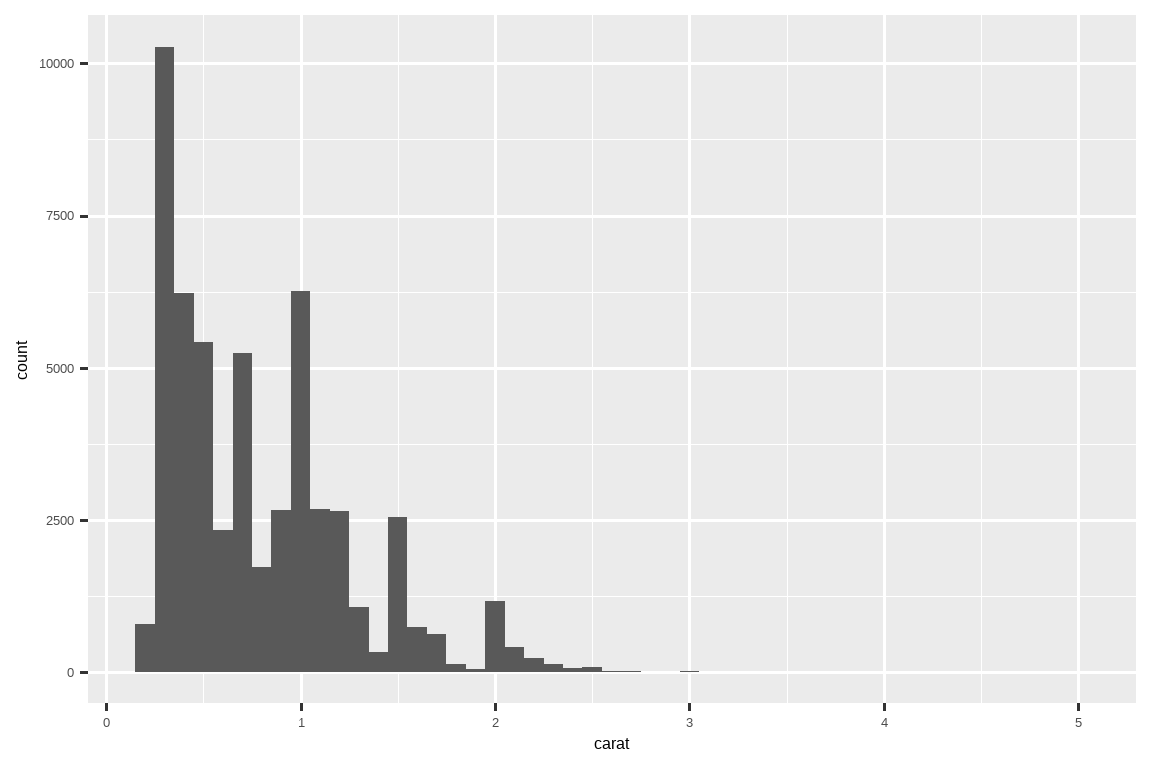
请注意,histogram() 返回一个 ggplot2 绘图对象,这意味着你仍然可以根据需要添加其他组件。只需记住从 |> 切换到 +:
diamonds |>
histogram(carat, 0.1) +
labs(x = "Size (in carats)", y = "Number of diamonds")25.4.1 更多变量
将更多变量加入进来也很直接。例如,你可能想通过叠加一条平滑曲线和一条直线来轻松地目测一个数据集是否是线性的:
# https://twitter.com/tyler_js_smith/status/1574377116988104704
linearity_check <- function(df, x, y) {
df |>
ggplot(aes(x = {{ x }}, y = {{ y }})) +
geom_point() +
geom_smooth(method = "loess", formula = y ~ x, color = "red", se = FALSE) +
geom_smooth(method = "lm", formula = y ~ x, color = "blue", se = FALSE)
}
starwars |>
filter(mass < 1000) |>
linearity_check(mass, height)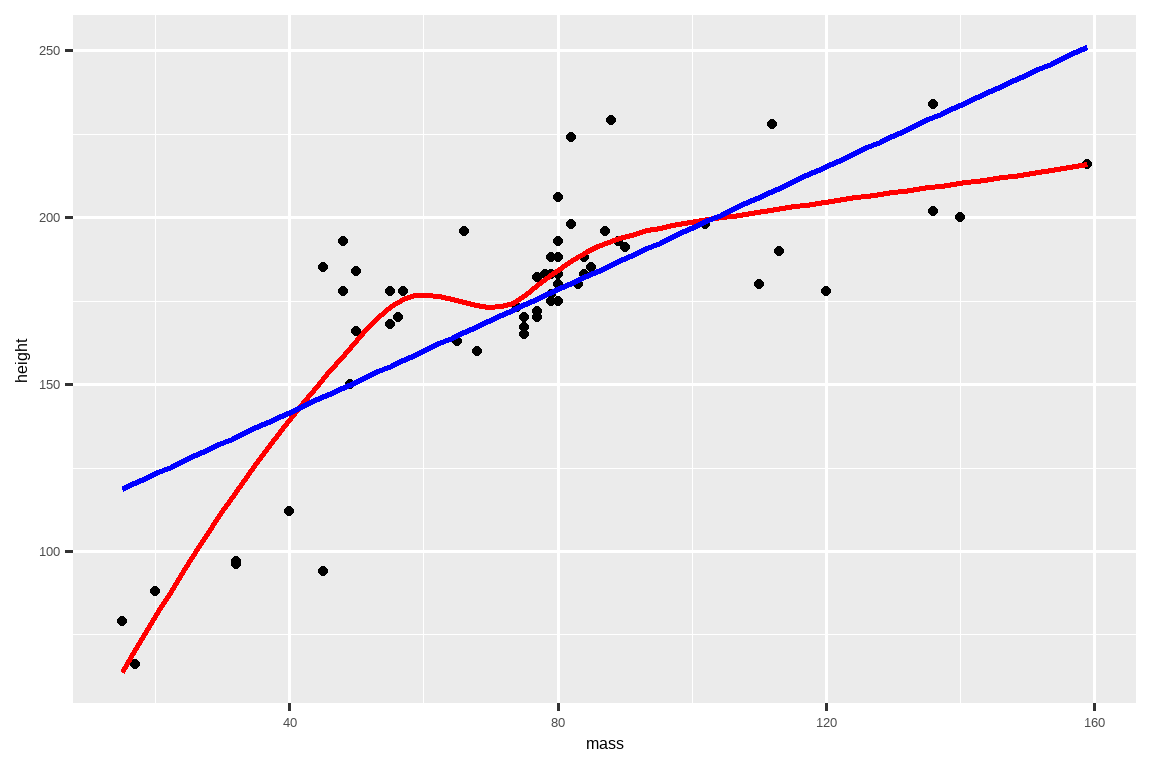
或者,对于点重叠问题严重的大型数据集,你可能想要一种替代彩色散点图的方法:
# https://twitter.com/ppaxisa/status/1574398423175921665
hex_plot <- function(df, x, y, z, bins = 20, fun = "mean") {
df |>
ggplot(aes(x = {{ x }}, y = {{ y }}, z = {{ z }})) +
stat_summary_hex(
aes(color = after_scale(fill)), # 使边框颜色与填充色相同
bins = bins,
fun = fun,
)
}
diamonds |> hex_plot(carat, price, depth)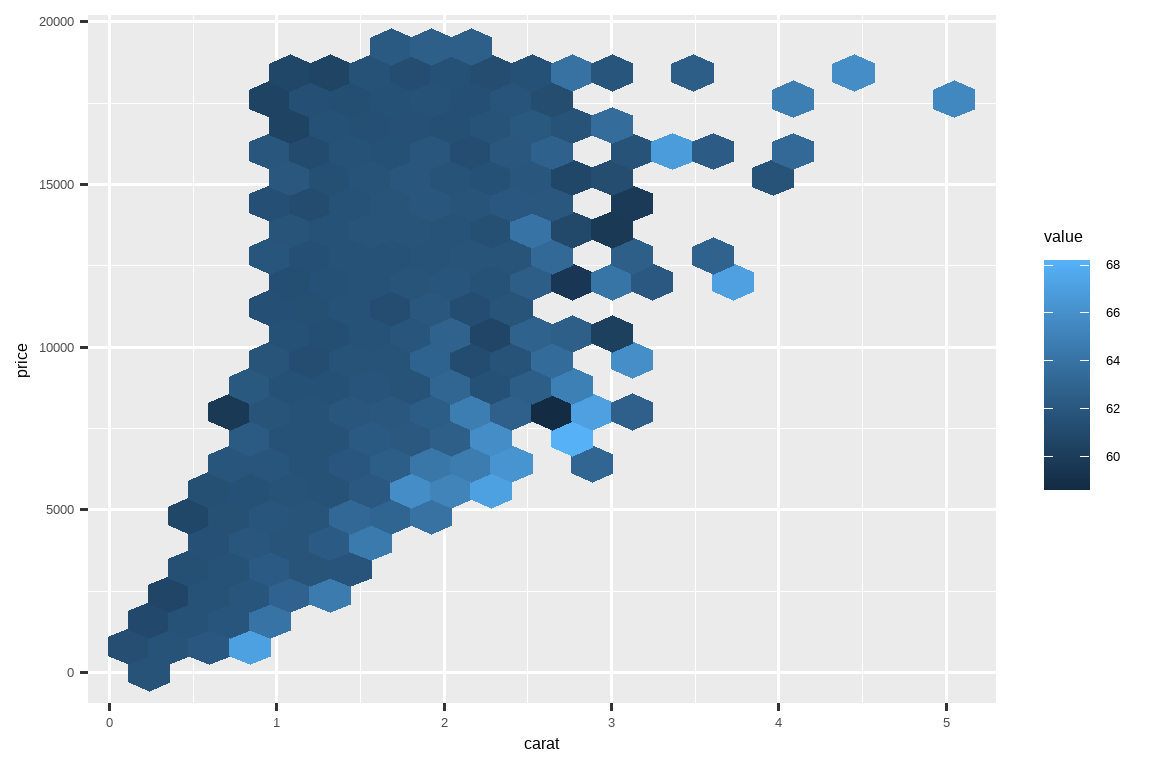
25.4.2 与其他 tidyverse 功能结合
一些最有用的辅助函数是将少量数据操作与 ggplot2 结合起来。例如,你可能想制作一个垂直条形图,并使用 fct_infreq() 自动按频率顺序对条形进行排序。由于条形图是垂直的,我们还需要反转通常的顺序,以使最高的值在顶部:
sorted_bars <- function(df, var) {
df |>
mutate({{ var }} := fct_rev(fct_infreq({{ var }}))) |>
ggplot(aes(y = {{ var }})) +
geom_bar()
}
diamonds |> sorted_bars(clarity)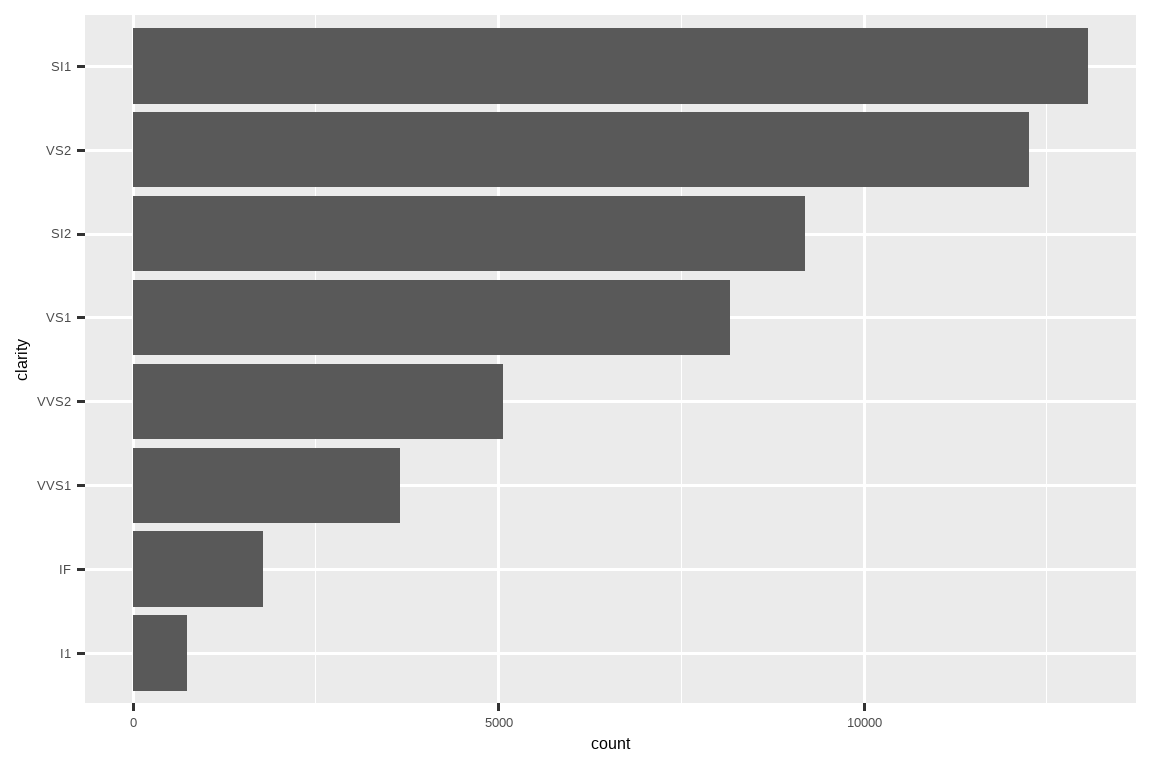
这里我们必须使用一个新的操作符 :=(通常被称为“海象操作符”),因为我们正在根据用户提供的数据生成变量名。变量名通常放在 = 的左侧,但 R 的语法不允许在 = 的左侧有除了单个字面名称之外的任何东西。为了解决这个问题,我们使用特殊的操作符 :=,整洁求值会将其与 = 完全相同地对待。
或者,你可能想方便地为数据的某个子集绘制条形图:
conditional_bars <- function(df, condition, var) {
df |>
filter({{ condition }}) |>
ggplot(aes(x = {{ var }})) +
geom_bar()
}
diamonds |> conditional_bars(cut == "Good", clarity)
你也可以发挥创意,用其他方式展示数据摘要。你可以在 https://gist.github.com/GShotwell/b19ef520b6d56f61a830fabb3454965b 找到一个很酷的应用;它使用坐标轴标签来显示最高值。随着你对 ggplot2 的了解越来越多,你函数的功能也会不断增强。
我们以一个更复杂的例子来结束:为你创建的图表添加标签。
25.4.3 标签
还记得我们之前给你看的直方图函数吗?
histogram <- function(df, var, binwidth = NULL) {
df |>
ggplot(aes(x = {{ var }})) +
geom_histogram(binwidth = binwidth)
}如果我们能用所使用的变量和组距来标记输出,那不是很好吗?为此,我们将不得不深入了解整洁求值的底层,并使用一个我们尚未提及的包中的函数:rlang。rlang 是一个低级包,几乎 tidyverse 中的所有其他包都在使用它,因为它实现了整洁求值(以及许多其他有用的工具)。
为了解决标签问题,我们可以使用 rlang::englue()。它的工作方式类似于 str_glue(),所以任何用 { } 包裹的值都将被插入到字符串中。但它也理解 {{ }},它会自动插入适当的变量名:
histogram <- function(df, var, binwidth) {
label <- rlang::englue("A histogram of {{var}} with binwidth {binwidth}")
df |>
ggplot(aes(x = {{ var }})) +
geom_histogram(binwidth = binwidth) +
labs(title = label)
}
diamonds |> histogram(carat, 0.1)
你可以在 ggplot2 图中任何想提供字符串的地方使用同样的方法。
25.4.4 练习
通过逐步实现以下每个步骤,构建一个功能丰富的绘图函数:
给定数据集以及
x和y变量,绘制一个散点图。添加一条最佳拟合线(即没有标准误差的线性模型)。
添加一个标题。
25.5 风格
R 不在乎你的函数或参数叫什么名字,但这些名字对人类来说却有很大的不同。理想情况下,你的函数名应该简短,但能清晰地唤起函数的功能。这很难!但清晰比简短更好,因为 RStudio 的自动补全功能使得输入长名称变得容易。
通常,函数名应该是动词,参数应该是名词。也有一些例外:如果函数计算的是一个非常众所周知的名词(即 mean() 比 compute_mean() 好),或者访问对象的某个属性(即 coef() 比 get_coefficients() 好),那么名词也是可以的。运用你的最佳判断,如果以后想到了更好的名字,不要害怕重命名函数。
# 太短
f()
# 不是动词,或不具描述性
my_awesome_function()
# 长,但清晰
impute_missing()
collapse_years()R 也不在乎你在函数中如何使用空白,但未来的读者会在乎。请继续遵循 Chapter 4 中的规则。此外,function() 后面应始终跟着花括号 ({}),并且内容应该额外缩进两个空格。这样通过扫视左边距,可以更容易地看到代码的层次结构。
# 缺少额外的两个空格
density <- function(color, facets, binwidth = 0.1) {
diamonds |>
ggplot(aes(x = carat, y = after_stat(density), color = {{ color }})) +
geom_freqpoly(binwidth = binwidth) +
facet_wrap(vars({{ facets }}))
}
# 管道缩进不正确
density <- function(color, facets, binwidth = 0.1) {
diamonds |>
ggplot(aes(x = carat, y = after_stat(density), color = {{ color }})) +
geom_freqpoly(binwidth = binwidth) +
facet_wrap(vars({{ facets }}))
}如你所见,我们建议在 {{ }} 内部多加一些空格。这使得有不寻常的事情发生变得非常明显。
25.5.1 练习
25.6 小结
在本章中,你学习了如何为三种有用的场景编写函数:创建向量、创建数据框或创建绘图。在此过程中,你看到了许多例子,希望这些例子能激发你的创造力,并为你提供一些关于函数如何帮助你的分析代码的想法。
我们只向你展示了函数入门的最低要求,还有更多内容需要学习。以下是一些可以深入学习的地方:
- 要了解更多关于使用整洁求值编程的知识,请参阅 programming with dplyr 和 programming with tidyr 中的有用秘籍,并在 What is data-masking and why do I need {{? 中学习更多理论知识。
- 要了解更多关于减少 ggplot2 代码重复的知识,请阅读 ggplot2 书籍的 Programming with ggplot2 章节。
- 有关函数风格的更多建议,请参阅 tidyverse 风格指南。
在下一章中,我们将深入探讨迭代,它为你提供了进一步减少代码重复的工具。