27 Base R 实战指南
27.1 引言
为了完成编程部分的学习,我们将带你快速浏览一些本书中未曾讨论但非常重要的 Base R 函数。 当你进行更多的编程工作时,这些工具会特别有用,它们也将帮助你阅读在实际工作中遇到的 R 代码。
在此,我们想再次提醒你,tidyverse 并非解决数据科学问题的唯一途径。 我们在本书中教授 tidyverse,是因为 tidyverse 系列包共享一套通用的设计理念,这增加了函数之间的一致性,使得学习和使用每一个新函数或包都变得更加容易。 不使用 Base R 是不可能使用 tidyverse 的,所以我们实际上已经教了你大量的 Base R 函数:从用于加载包的 library(),到用于数值摘要的 sum() 和 mean(),再到因子 (factor)、日期 (date) 和 POSIXct 数据类型,当然还有所有基本运算符,如 +、-、/、*、|、& 和 !。 到目前为止,我们还没有重点介绍 Base R 的工作流程,因此在本章中,我们将重点介绍其中的一些。
读完本书后,你将学习到使用 Base R、data.table 和其他包来解决同样问题的其他方法。 当你开始阅读他人编写的 R 代码时,尤其是在使用 StackOverflow 时,你无疑会遇到这些其他方法。 编写混合使用多种方法的代码是完全可以的,不要让任何人告诉你这有什么不对!
在本章中,我们将重点关注四个主要主题:使用 [ 进行子集选取,使用 [[ 和 $ 进行子集选取,apply 函数族,以及 for 循环。 最后,我们将简要讨论两个必不可少的绘图函数。
27.1.1 前提条件
这个包侧重于 Base R,因此没有真正的前提条件,但我们将加载 tidyverse 以便解释一些差异。
27.2 使用 [ 选取多个元素
[ 用于从向量和数据框中提取子组件,调用形式为 x[i] 或 x[i, j]。 在本节中,我们将向你介绍 [ 的强大功能,首先展示如何将其用于向量,然后说明同样的原理如何直接扩展到二维 (2d) 结构,如数据框。 接着,我们将通过展示各种 dplyr 动词是如何作为 [ 的特例,来帮助你巩固这些知识。
27.2.1 向量子集选取
你可以用五种主要类型的东西来对向量进行子集选取,即 x[i] 中的 i 可以是:
-
一个正整数向量。 用正整数进行子集选取会保留这些位置上的元素:
通过重复一个位置,你实际上可以得到比输入更长的输出,这使得“子集选取 (subsetting)”这个术语有点名不副实。
x[c(1, 1, 5, 5, 5, 2)] #> [1] "one" "one" "five" "five" "five" "two" -
一个负整数向量。 负数值会丢弃指定位置的元素:
x[c(-1, -3, -5)] #> [1] "two" "four" -
一个逻辑向量。 用逻辑向量进行子集选取会保留所有对应
TRUE值的值。 这在与比较函数结合使用时最为有用。与
filter()不同,NA索引将在输出中作为NA包含进来。 -
一个字符向量。 如果你有一个命名的向量,你可以用字符向量来对其进行子集选取:
与使用正整数进行子集选取一样,你可以使用字符向量来复制单个条目。
空。 最后一种子集选取是空,即
x[],它返回完整的x。 这对于向量的子集选取没什么用,但我们稍后会看到,在对二维结构(如 tibble)进行子集选取时它非常有用。
27.2.2 数据框子集选取
你可以用很多不同的方式1 对数据框使用 [,但最重要的方式是使用 df[rows, cols] 独立地选择行和列。这里的 rows 和 cols 是如上所述的向量。 例如,df[rows, ] 和 df[, cols] 分别只选择行或只选择列,使用空子集来保留另一维度。
这里有几个例子:
df <- tibble(
x = 1:3,
y = c("a", "e", "f"),
z = runif(3)
)
# 选择第一行和第二列
df[1, 2]
#> # A tibble: 1 × 1
#> y
#> <chr>
#> 1 a
# 选择所有行以及 x 和 y 列
df[, c("x" , "y")]
#> # A tibble: 3 × 2
#> x y
#> <int> <chr>
#> 1 1 a
#> 2 2 e
#> 3 3 f
# 选择 `x` 大于 1 的行和所有列
df[df$x > 1, ]
#> # A tibble: 2 × 3
#> x y z
#> <int> <chr> <dbl>
#> 1 2 e 0.834
#> 2 3 f 0.601我们稍后会回到 $,但你应该能从上下文中猜出 df$x 的作用:它从 df 中提取 x 变量。 我们在这里需要使用它,因为 [ 不使用整洁求值 (tidy evaluation),所以你需要明确 x 变量的来源。
在 [ 的使用上,tibble 和 data frame 之间有一个重要的区别。 在本书中,我们主要使用 tibble,它是一种数据框,但它们调整了一些行为以使你的工作更轻松一些。 在大多数地方,你可以互换使用“tibble”和“data frame”,所以当我们想特别指出 R 的内置 data frame 时,我们会写成 data.frame。 如果 df 是一个 data.frame,那么如果 col 选择单个列,df[, cols] 将返回一个向量;如果它选择多个列,则返回一个数据框。 如果 df 是一个 tibble,那么 [ 将始终返回一个 tibble。
df1 <- data.frame(x = 1:3)
df1[, "x"]
#> [1] 1 2 3
df2 <- tibble(x = 1:3)
df2[, "x"]
#> # A tibble: 3 × 1
#> x
#> <int>
#> 1 1
#> 2 2
#> 3 3一种避免与 data.frame 产生这种歧义的方法是明确指定 drop = FALSE:
df1[, "x" , drop = FALSE]
#> x
#> 1 1
#> 2 2
#> 3 327.2.3 dplyr 等价操作
一些 dplyr 动词是 [ 的特例:
-
filter()等价于使用逻辑向量对行进行子集选取,并注意排除缺失值:在实际应用中,另一个常见的技巧是使用
which()来达到丢弃缺失值的副作用:df[which(df$x > 1), ]。 -
arrange()等价于使用整数向量对行进行子集选取,这个向量通常由order()创建:你可以使用
order(decreasing = TRUE)来按降序对所有列进行排序,或者使用-rank(col)来单独按降序对列进行排序。 -
select()和relocate()都类似于使用字符向量对列进行子集选取:
Base R 还提供了一个结合了 filter() 和 select() 功能的函数2,名为 subset():
这个函数是 dplyr 许多语法设计的灵感来源。
27.2.4 练习
-
创建函数,输入一个向量,然后返回:
- 偶数位置上的元素。
- 除了最后一个值之外的所有元素。
- 只有偶数值(并且没有缺失值)。
为什么
x[-which(x > 0)]和x[x <= 0]不一样? 阅读which()的文档并做一些实验来找出答案。
27.3 使用 $ 和 [[ 选取单个元素
[ 用于选取多个元素,与之配对的是 [[ 和 $,它们用于提取单个元素。 在本节中,我们将向你展示如何使用 [[ 和 $ 从数据框中提取列,讨论 data.frame 和 tibble 之间更多的几个区别,并强调在与列表一起使用时 [ 和 [[ 之间的一些重要差异。
27.3.1 数据框
[[ 和 $ 可以用来从数据框中提取列。 [[ 可以通过位置或名称访问,而 $ 专门用于按名称访问:
它们也可以用来创建新列,这是 mutate() 在 Base R 中的等价操作:
tb$z <- tb$x + tb$y
tb
#> # A tibble: 4 × 3
#> x y z
#> <int> <dbl> <dbl>
#> 1 1 10 11
#> 2 2 4 6
#> 3 3 1 4
#> 4 4 21 25还有其他几种 Base R 创建新列的方法,包括使用 transform()、with() 和 within()。 Hadley 在 https://gist.github.com/hadley/1986a273e384fb2d4d752c18ed71bedf 收集了一些例子。
在进行快速摘要时,直接使用 $ 很方便。 例如,如果你只想找出最大钻石的克拉数或 cut 的可能值,就不需要使用 summarize():
dplyr 也提供了一个等价于 [[/$ 的函数,我们在 Chapter 3 中没有提到:pull()。 pull() 接受一个变量名或变量位置,并只返回那一列。 这意味着我们可以重写上面的代码来使用管道:
27.3.2 Tibbles
在 $ 的使用上,tibble 和 Base data.frame 之间有几个重要的区别。 Data frame 会匹配任何变量名的前缀(即所谓的部分匹配 (partial matching)),并且如果一列不存在也不会报错:
df <- data.frame(x1 = 1)
df$x
#> [1] 1
df$z
#> NULLTibble 更为严格:它们只精确匹配变量名,并且如果你尝试访问的列不存在,它们会生成一个警告:
tb <- tibble(x1 = 1)
tb$x
#> Warning: Unknown or uninitialised column: `x`.
#> NULL
tb$z
#> Warning: Unknown or uninitialised column: `z`.
#> NULL因此,我们有时开玩笑说 tibble 是“又懒又暴躁”:它们做得更少,抱怨得更多。
27.3.3 列表
[[ 和 $ 在处理列表时也非常重要,理解它们与 [ 的区别至关重要。 让我们用一个名为 l 的列表来说明这些差异:
-
[提取一个子列表。 无论你提取多少个元素,结果总是一个列表。与向量一样,你可以用逻辑、整数或字符向量进行子集选取。
-
[[和$从列表中提取单个组件。 它们会从列表中移除一个层级。
[ 和 [[ 之间的区别对于列表尤为重要,因为 [[ 会深入到列表中,而 [ 返回一个新的、更小的列表。 为了帮助你记住这个区别,请看 Figure 27.1 中展示的那个不寻常的胡椒瓶。 如果这个胡椒瓶是你的列表 pepper,那么 pepper[1] 就是一个装有单个胡椒包的胡椒瓶。 pepper[2] 看起来一样,但会装有第二个胡椒包。 pepper[1:2] 将是一个装有两个胡椒包的胡椒瓶。 而 pepper[[1]] 则会提取出胡椒包本身。
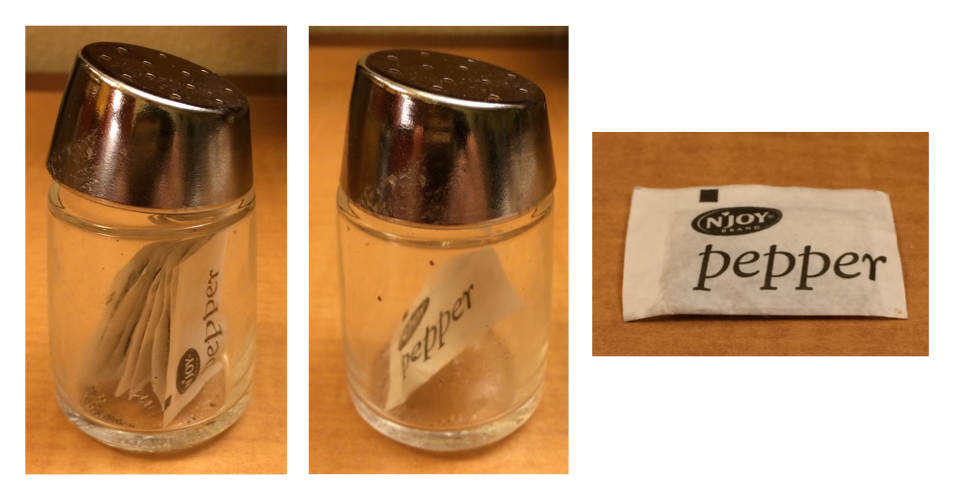
pepper[1]。 (右) pepper[[1]]。
当你对数据框使用一维 [ 时,同样的原理也适用:df["x"] 返回一个单列数据框,而 df[["x"]] 返回一个向量。
27.3.4 练习
当你用一个比向量长度大的正整数对
[[进行子集选取时会发生什么? 当你用一个不存在的名称进行子集选取时会发生什么?pepper[[1]][1]会是什么?pepper[[1]][[1]]呢?
27.4 Apply 函数族
在 Chapter 26 中,你学习了 tidyverse 的迭代技术,如 dplyr::across() 和 map 系列函数。 在本节中,你将学习它们的 Base R 等价物,即 apply 函数族。 在此语境下,apply 和 map 是同义词,因为“将一个函数映射 (map) 到向量的每个元素上”的另一种说法是“将一个函数应用 (apply) 到向量的每个元素上”。 这里我们将为你简要介绍这个函数族,以便你在实际中能认出它们。
这个函数族中最重要的成员是 lapply(),它与 purrr::map() 非常相似3。 事实上,因为我们没有使用 map() 的任何更高级的功能,你可以将 Chapter 26 中所有的 map() 调用都替换为 lapply()。
没有完全等同于 across() 的 Base R 函数,但你可以通过结合使用 [ 和 lapply() 来接近其功能。 这是可行的,因为在底层,数据框是列的列表,所以对数据框调用 lapply() 会将函数应用于每一列。
df <- tibble(a = 1, b = 2, c = "a", d = "b", e = 4)
# 首先找到数值列
num_cols <- sapply(df, is.numeric)
num_cols
#> a b c d e
#> TRUE TRUE FALSE FALSE TRUE
# 然后用 lapply() 转换每一列,再替换原始值
df[, num_cols] <- lapply(df[, num_cols, drop = FALSE], \(x) x * 2)
df
#> # A tibble: 1 × 5
#> a b c d e
#> <dbl> <dbl> <chr> <chr> <dbl>
#> 1 2 4 a b 8上面的代码使用了一个新函数 sapply()。 它与 lapply() 相似,但它总是尝试简化结果,因此其名称中的 s 代表简化 (simplify),这里它产生了一个逻辑向量而不是一个列表。 我们不推荐在编程中使用它,因为简化可能会失败并给你一个意想不到的类型,但对于交互式使用来说通常没问题。 purrr 有一个类似的函数叫 map_vec(),我们在 Chapter 26 中没有提到。
Base R 提供了一个比 sapply() 更严格的版本,叫做 vapply(),是vector apply (向量应用) 的缩写。 它接受一个额外的参数来指定预期的类型,确保无论输入如何,简化过程都以相同的方式发生。 例如,我们可以将上面的 sapply() 调用替换为这个 vapply(),在这里我们指定期望 is.numeric() 返回一个长度为 1 的逻辑向量:
sapply() 和 vapply() 之间的区别在它们位于函数内部时非常重要(因为它对函数对异常输入的鲁棒性有很大影响),但在数据分析中通常无关紧要。
apply 函数族的另一个重要成员是 tapply(),它计算单个分组摘要:
diamonds |>
group_by(cut) |>
summarize(price = mean(price))
#> # A tibble: 5 × 2
#> cut price
#> <ord> <dbl>
#> 1 Fair 4359.
#> 2 Good 3929.
#> 3 Very Good 3982.
#> 4 Premium 4584.
#> 5 Ideal 3458.
tapply(diamonds$price, diamonds$cut, mean)
#> Fair Good Very Good Premium Ideal
#> 4358.758 3928.864 3981.760 4584.258 3457.542不幸的是,tapply() 将其结果返回在一个命名的向量中,如果你想将多个摘要和分组变量收集到一个数据框中,就需要一些技巧(当然可以不这样做,直接使用自由浮动的向量,但根据我们的经验,这只是推迟了工作)。 如果你想看看如何使用 tapply() 或其他 Base R 技术来执行其他分组摘要,Hadley 在一个 gist 中收集了一些技巧。
apply 函数族的最后一个成员是其同名函数 apply(),它用于处理矩阵和数组。 特别要注意 apply(df, 2, something),这是一种缓慢且可能危险的方式来实现 lapply(df, something)。 这在数据科学中很少出现,因为我们通常处理的是数据框而不是矩阵。
27.5 for 循环
for 循环是 apply 和 map 家族在底层都使用的迭代基本构建块。 for 循环是强大而通用的工具,随着你成为更富经验的 R 程序员,学习它们非常重要。 for 循环的基本结构如下:
for (element in vector) {
# 对 element 执行某些操作
}for 循环最直接的用途是实现与 walk() 相同的效果:对列表的每个元素调用某个具有副作用的函数。 例如,在 Section 26.4.1 中,我们没有使用 walk():
paths |> walk(append_file)而是可以使用 for 循环:
for (path in paths) {
append_file(path)
}如果你想保存 for 循环的输出,事情就会变得棘手一些,例如像我们在 Chapter 26 中做的那样,读取一个目录中所有的 excel 文件:
paths <- dir("data/gapminder", pattern = "\\.xlsx$", full.names = TRUE)
files <- map(paths, readxl::read_excel)你可以使用几种不同的技术,但我们建议事先明确输出会是什么样子。 在这种情况下,我们将需要一个与 paths 长度相同的列表,我们可以用 vector() 来创建它:
然后,我们不遍历 paths 的元素,而是遍历它们的索引,使用 seq_along() 为 paths 的每个元素生成一个索引:
seq_along(paths)
#> [1] 1 2 3 4 5 6 7 8 9 10 11 12使用索引很重要,因为它允许我们将输入中的每个位置与输出中的相应位置联系起来:
for (i in seq_along(paths)) {
files[[i]] <- readxl::read_excel(paths[[i]])
}要将 tibble 列表合并为单个 tibble,你可以使用 do.call() + rbind():
do.call(rbind, files)
#> # A tibble: 1,704 × 5
#> country continent lifeExp pop gdpPercap
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Afghanistan Asia 28.8 8425333 779.
#> 2 Albania Europe 55.2 1282697 1601.
#> 3 Algeria Africa 43.1 9279525 2449.
#> 4 Angola Africa 30.0 4232095 3521.
#> 5 Argentina Americas 62.5 17876956 5911.
#> 6 Australia Oceania 69.1 8691212 10040.
#> # ℹ 1,698 more rows与其先创建一个列表并在过程中保存结果,一个更简单的方法是逐个构建数据框:
out <- NULL
for (path in paths) {
out <- rbind(out, readxl::read_excel(path))
}我们建议避免这种模式,因为当向量非常长时,它会变得非常慢。 这就是“for 循环很慢”这个经久不衰的谣言的来源:它们本身不慢,但迭代地增长一个向量是慢的。
27.6 图形
许多不常使用 tidyverse 的 R 用户也偏爱使用 ggplot2 进行绘图,因为它具有一些有用的特性,如合理的默认设置、自动生成图例和现代的外观。 然而,Base R 的绘图函数仍然很有用,因为它们非常简洁——做一个基本的探索性图表只需要很少的打字。
在实际应用中,你会看到两种主要的 Base R 图形:散点图和直方图,分别由 plot() 和 hist() 生成。 这里有一个来自 diamonds 数据集的快速示例:
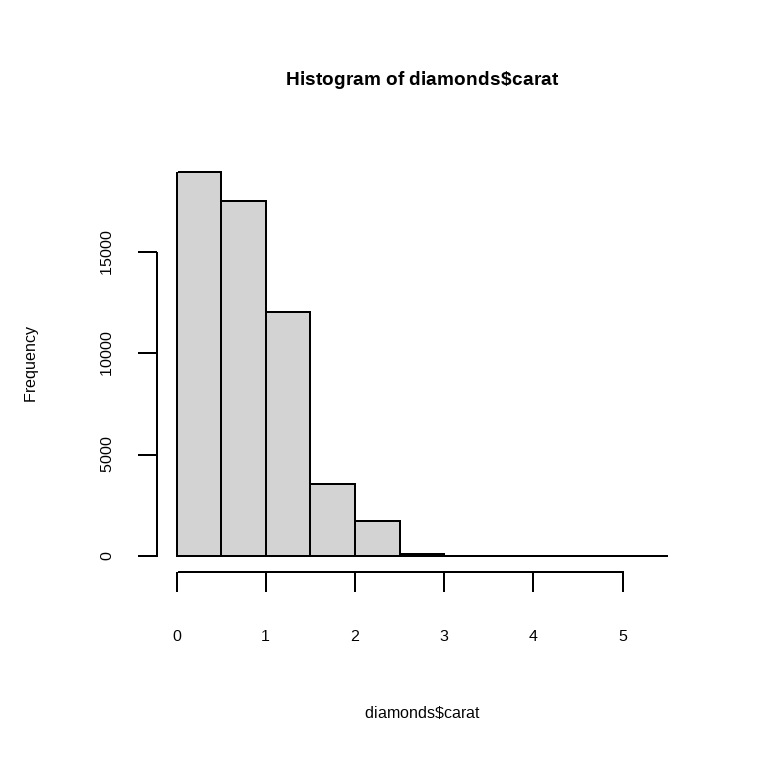
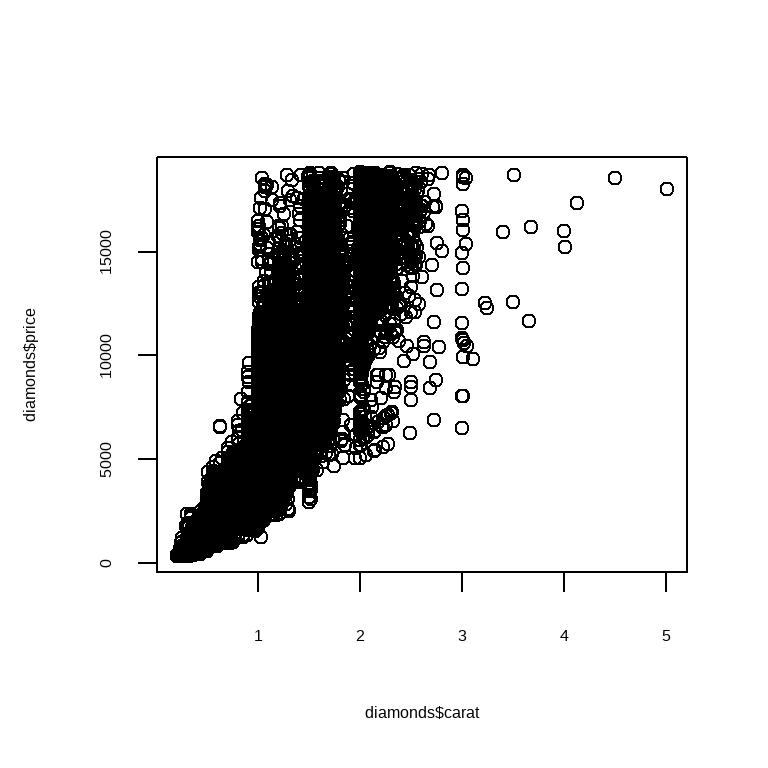
请注意,Base R 的绘图函数作用于向量,所以你需要使用 $ 或其他技术从数据框中提取列。
27.7 总结
在本章中,我们向你展示了一系列用于子集选取和迭代的 Base R 函数。 与本书其他地方讨论的方法相比,这些函数更倾向于“向量”风格,而不是“数据框”风格,因为 Base R 函数倾向于接受单个向量,而不是一个数据框和一些列的规范。 这通常使编程工作更容易,因此当你编写更多函数并开始编写自己的包时,它变得更加重要。
本章结束了本书的编程部分。 你已经在成为一名不仅使用 R 的数据科学家,而且是能够用 R 编程 的数据科学家的道路上迈出了坚实的一步。 我们希望这些章节激发了你对编程的兴趣,并期待你在本书之外学习更多内容。
阅读 https://adv-r.hadley.nz/subsetting.html#subset-multiple 来了解如何像处理一维对象一样对数据框进行子集选取,以及如何使用矩阵对其进行子集选取。↩︎
但它不会对分组的数据框进行特殊处理,也不支持像
starts_with()这样的选择辅助函数。↩︎它只是缺少了一些方便的功能,比如进度条和在出错时报告是哪个元素导致了问题。↩︎